xv6学习,Lab5-Lab9合集
六、Lab6: Multithreading
本次实验需要实现线程之间的切换,使用多个线程来加速程序,并实现一个屏障。根据实验提示需要先阅读实验手册 Scheduling 部分及相关代码,其主要内容如下:
任何操作系统运行的进程数量都可能超过计算机的 CPU 数量,因此需要一个计划来在进程之间分时共享 CPU。理想情况下,这种共享对用户进程是透明的。一种常见的方法是通过将进程复用到硬件 CPU 上,为每个进程营造出它拥有自己的虚拟 CPU 的错觉。本章将解释 xv6 是如何实现这种复用的。
实现 Multiplexing(多路复用)
Xv6 通过在两种情况下将每个 CPU 从一个进程切换到另一个进程来实现复用。首先,当一个进程等待设备或管道 I/O 完成、等待子进程退出或在 sleep 系统调用中等待时,xv6 的睡眠和唤醒机制会进行切换。其次,xv6 会定期强制进行切换,以应对长时间计算而不睡眠的进程。这种复用营造出每个进程都有自己的 CPU 的错觉,就像 xv6 使用内存分配器和硬件页表来营造每个进程都有自己自己的内存的错觉一样。 实现复用较为复杂:
- 如何从一个进程切换到另一个进程?尽管上下文切换的概念很简单,但在 xv6 中,其实现是一些最不透明的代码。
- 如何以对用户进程透明的方式强制进行切换?Xv6 使用了一种标准技术,其中硬件定时器的中断驱动上下文切换。
- 所有的 CPU 在同一组共享进程之间进行切换,因此需要一个锁定方案来避免竞争条件。
- 当一个进程退出时,必须释放其内存和其他资源,但它自己不能完成所有这些操作,例如,它不能在仍在使用内核栈时释放自己的内核栈。
- 多核机器的每个核心必须记住它正在执行的是哪个进程,以便系统调用影响正确进程的内核状态。
- 睡眠和唤醒允许一个进程放弃 CPU 并等待被另一个进程或中断唤醒。需要注意避免出现导致唤醒通知丢失的竞争条件。
Code: Context switching
从一个用户进程切换到另一个用户进程所涉及的步骤:从旧进程的用户态到内核态的转换(系统调用或中断),切换到当前 CPU 的调度器线程的上下文切换,切换到新进程的内核线程的上下文切换,以及返回到用户级进程的陷阱返回。xv6为每个 CPU 都提供一个专用线程(保存的寄存器和栈) 调度器,因为调度器在旧进程的内核栈上执行是不安全的:其他一些核心可能会唤醒该进程并运行它,如果在两个不同的核心上使用相同的栈,那将是一场灾难。从一个线程切换到另一个线程涉及保存旧线程的 CPU 寄存器,并恢复新线程之前保存的寄存器;栈指针和程序计数器被保存和恢复这一事实意味着 CPU 将切换栈并切换它正在执行的代码。 函数 swtch 为内核线程切换执行保存和恢复操作。swtch 并不直接了解线程;它只是保存和恢复一组 32 位 RISC-V 寄存器,称为上下文。当一个进程需要放弃 CPU 时,该进程的内核线程会调用 swtch 来保存其自身的上下文并返回到调度器上下文。
当进程从用户态进入trap后,位于kernel/trap.c中的 usertrap()函数会判断其是否需要切换到另一个进程,若需要就调用 yield。yield 进而调用 sched,sched 又调用 swtch,将当前上下文保存到 p->context 中,并切换到之前保存在 cpu->context 中的调度器上下文。相关的结构体和代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80// kernel/proc.h:2
// Saved registers for kernel context switches.
struct context {
uint64 ra;
uint64 sp;
// callee-saved
uint64 s0;
uint64 s1;
uint64 s2;
uint64 s3;
uint64 s4;
uint64 s5;
uint64 s6;
uint64 s7;
uint64 s8;
uint64 s9;
uint64 s10;
uint64 s11;
};
// kernel/proc.h:21
// Per-CPU state.
struct cpu {
struct proc *proc; // The process running on this cpu, or null.
struct context context; // swtch() here to enter scheduler().
int noff; // Depth of push_off() nesting.
int intena; // Were interrupts enabled before push_off()?
};
// kernel/trap.c
void
usertrap(void)
{
// 省略了若干行
// 如果是定时器中断,就调用yield来放弃CPU
if(which_dev == 2)
yield();
usertrapret();
}
// kernel/proc.c:505
// 放弃CPU
void
yield(void)
{
// 获取进程并将进程的状态从RUNNING设置为RUNNABLE
struct proc *p = myproc();
acquire(&p->lock);
p->state = RUNNABLE;
// 调用sched开始调度
sched();
release(&p->lock);
}
// 切换到调度器
// 必须仅持有 p->lock 锁并且已经更改了 proc->state
// 保存和恢复intena,因为 intena 是此内核线程的属性,而不是此 CPU 的属性
// 理想情况下应该是 proc->intena 和 proc->noff
// 但那样会在少数持有锁但没有进程的地方出现问题
void
sched(void)
{
int intena; // 定义一个整数变量 intena,用于保存中断使能状态
struct proc *p = myproc();
// 检查状态,不正常触发panic
if(!holding(&p->lock))
panic("sched p->lock");
if(mycpu()->noff!= 1)
panic("sched locks");
if(p->state == RUNNING)
panic("sched running");
if(intr_get())
panic("sched interruptible");
// 保存当前CPU的中断状态
intena = mycpu()->intena;
// 进行上下文切换
swtch(&p->context, &mycpu()->context);
// 恢复当前CPU的中断状态
mycpu()->intena = intena;
}swtch(kernel/swtch.S:3)只保存被调用者保存的寄存器;C 编译器会在调用者中生成代码,将调用者保存的寄存器保存到栈上。swtch 知道 struct context 中每个寄存器字段的偏移量。它不保存程序计数器。相反,swtch 保存 ra 寄存器,该寄存器保存了调用 swtch 的返回地址。现在,swtch 从新的上下文中恢复寄存器,该上下文保存了之前的 swtch 保存的寄存器值。当 swtch 返回时,它会返回到由恢复的 ra 寄存器所指向的指令,也就是新线程之前调用 swtch 的指令。此外,它会在新线程的栈上返回,因为这是恢复的 sp 所指向的位置。 在我们的示例中,sched 调用 swtch 以切换到 cpu->context,即每个 CPU 的调度器上下文。该上下文是在过去调度器调用 swtch(kernel/proc.c:463)以切换到现在正在放弃 CPU 的进程时保存的。当我们一直在跟踪的 swtch 返回时,它不是返回到 sched,而是返回到 scheduler,并且栈指针位于当前 CPU 的调度器栈中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39# Context switch
#
# void swtch(struct context *old, struct context *new);
#
# Save current registers in old. Load from new.
.globl swtch
swtch:
sd ra, 0(a0)
sd sp, 8(a0)
sd s0, 16(a0)
sd s1, 24(a0)
sd s2, 32(a0)
sd s3, 40(a0)
sd s4, 48(a0)
sd s5, 56(a0)
sd s6, 64(a0)
sd s7, 72(a0)
sd s8, 80(a0)
sd s9, 88(a0)
sd s10, 96(a0)
sd s11, 104(a0)
ld ra, 0(a1)
ld sp, 8(a1)
ld s0, 16(a1)
ld s1, 24(a1)
ld s2, 32(a1)
ld s3, 40(a1)
ld s4, 48(a1)
ld s5, 56(a1)
ld s6, 64(a1)
ld s7, 72(a1)
ld s8, 80(a1)
ld s9, 88(a1)
ld s10, 96(a1)
ld s11, 104(a1)
retCode: Scheduling
上一节探讨了 swtch 的底层细节;现在我们将 swtch 视为既定的,并研究如何通过调度器从一个进程的内核线程切换到另一个进程。调度器以每个 CPU 上的一个特殊线程的形式存在,每个线程都运行调度器函数。这个函数负责选择下一个要运行的进程。一个想要放弃 CPU 的进程必须获取自己的进程锁 p->lock,释放它持有的任何其他锁,更新自己的状态(p->state),然后调用 sched。在 yield(kernel/proc.c:503)、sleep 和 exit 中可以看到这个序列。sched 会再次检查其中的一些要求(kernel/proc.c:487 - 492),然后检查一个隐含的条件:由于持有一个锁,所以应该禁用中断。最后,sched 调用 swtch 将当前上下文保存到 p->context 中,并切换到 cpu->context 中的调度器上下文。swtch 会在调度器的栈上返回,就好像调度器的 swtch 已经返回了一样(kernel/proc.c:463)。调度器继续其 for 循环,找到一个要运行的进程,切换到该进程,然后这个循环重复进行。 我们刚刚看到,xv6 在调用 swtch 时会持有 p->lock:swtch 的调用者必须已经持有该锁,并且锁的控制权会传递给切换到的代码。这种关于锁的约定是不寻常的;通常,获取锁的线程也负责释放锁,这样更容易推断其正确性。对于上下文切换,有必要打破这个约定,因为 p->lock 保护的是进程的状态和上下文字段的不变量,而在 swtch 执行期间这些不变量并不成立。如果在 swtch 期间不持有 p->lock,可能会出现的一个问题示例是:在 yield 将其状态设置为 RUNNABLE 之后,但在 swtch 使其停止使用自己的内核栈之前,另一个 CPU 可能会决定运行该进程。结果将是两个 CPU 在同一个栈上运行,这会导致混乱。 内核线程放弃 CPU 的唯一地方是在 sched 中,并且它总是切换到调度器中的同一个位置,而调度器(几乎)总是切换到之前调用过 sched 的某个内核线程。因此,如果要打印出 xv6 切换线程的行号,将会观察到以下简单模式:(kernel/proc.c:463),(kernel/proc.c:497),(kernel/proc.c:463),(kernel/proc.c:497),等等。通过线程切换有意地将控制权相互转移的程序有时被称为协同程序;在这个例子中,sched 和 scheduler 是彼此的协同程序。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37// 每个CPU的进程调度器
// 每个CPU在完成自身设置后会调用 scheduler() 函数。
// scheduler() 函数不会返回,它会循环执行以下操作:
// 选择一个要运行的进程
// 通过 swtch 切换到该进程并开始运行
// 最终,该进程通过 swtch 控制转移回调度器
void
scheduler(void)
{
struct proc *p;
struct cpu *c = mycpu();
// 将当前CPU上正在运行的进程设置到0,以表示没有进程在运行
c->proc = 0;
for(;;){ // 无限循环
// 最近运行的进程可能关闭了中断,将其打开以避免在所有进程都在等待时出现死锁
// 打开中断
intr_on();
// 遍历所有进程
for(p = proc; p < &proc[NPROC]; p++) {
acquire(&p->lock);
// 如果进程状态为可运行(即是空闲状态)
if(p->state == RUNNABLE) {
// 将进程状态设置为正在运行
p->state = RUNNING;
// 将当前CPU上正在运行的进程设置为当前进程
c->proc = p;
// 切换到该进程的上下文
swtch(&c->context, &p->context);
// 进程当前的运行已完成。
// 它应该在返回之前更改其 p->state 状态。
// 将当前CPU上正在运行的进程设置为0
c->proc = 0;
}
release(&p->lock);
}
}
}有一种情况下,调度器对 swtch 的调用不会在 sched 中结束。allocproc 将新进程的上下文 ra 寄存器设置为 forkret(kernel/proc.c:515),以便其第一次 swtch “返回”到该函数的起始位置。forkret 的存在是为了释放 p->lock;否则,由于新进程需要像从 fork 函数返回一样返回到用户空间,它可能会从 usertrapret 开始。 scheduler(kernel/proc.c:445)运行一个循环:找到一个要运行的进程,运行它直到它让出,然后重复。调度器在进程表中循环查找一个可运行的进程,即 p->state == RUNNABLE 的进程。一旦找到一个进程,它会设置每个 CPU 的当前进程变量 c->proc,将该进程标记为 RUNNING,然后调用 swtch 来开始运行它(kernel/proc.c:458 - 463)。 思考调度代码结构的一种方式是,它对每个进程强制执行一组不变量,并且在这些不变量不成立时持有 p->lock。一个不变量是,如果一个进程处于 RUNNING 状态,那么定时器中断的 yield 必须能够安全地从该进程切换出去;这意味着 CPU 寄存器必须保存该进程的寄存器值(即 swtch 尚未将它们移动到一个上下文中),并且 c->proc 必须指向该进程。另一个不变量是,如果一个进程是 RUNNABLE 状态,那么空闲 CPU 的调度器运行它必须是安全的;这意味着 p->context 必须保存该进程的寄存器(即它们实际上不在实际的寄存器中),没有 CPU 在该进程的内核栈上执行,并且没有 CPU 的 c->proc 指向该进程。请注意,在持有 p->lock 时,这些属性通常不成立。 维护上述不变量是 xv6 经常在一个线程中获取 p->lock 并在另一个线程中释放它的原因,例如在 yield 中获取并在 scheduler 中释放。一旦 yield 开始修改一个正在运行的进程的状态以使其变为 RUNNABLE,必须保持锁的持有状态,直到恢复不变量:最早的正确释放点是在 scheduler(在其自己的栈上运行)清除 c->proc 之后。类似地,一旦 scheduler 开始将一个 RUNNABLE 进程转换为 RUNNING,在内核线程完全运行之前(例如在 yield 中的 swtch 之后)不能释放锁。
Code: mycpu and myproc
函数 mycpu(kernel/proc.c:74)返回一个指向当前 CPU 的 struct cpu 的指针。RISC-V 为其 CPU 编号,为每个 CPU 赋予一个 hartid。Xv6 确保在内核中,每个 CPU 的 hartid 都存储在该 CPU 的 tp 寄存器中。这使得 mycpu 能够使用 tp 作为索引,在一个 cpu 结构数组中找到正确的那个。
确保 CPU 的 tp 始终保存该 CPU 的 hartid 有点复杂。start 在 CPU 启动序列的早期,仍处于机器模式时设置 tp 寄存器(kernel/start.c:51)。usertrapret 将 tp 保存在跳板页中,因为用户进程可能会修改 tp。最后,uservec 在从用户空间进入内核时恢复保存的 tp(kernel/trampoline.S:77)。 编译器保证永远不会使用 tp 寄存器。如果 xv6 可以在需要时随时向 RISC-V 硬件询问当前的 hartid 会更方便,但 RISC-V 只允许在机器模式下这样做,而在监管模式下不行。 cpuid 和 mycpu 的返回值是脆弱的:如果定时器中断并导致线程让出,然后移动到不同的 CPU,之前返回的值将不再正确。为避免此问题,xv6 要求调用者禁用中断,并在使用完返回的 struct cpu 后再启用它们。 函数 myproc(kernel/proc.c:83)返回当前 CPU 上正在运行的进程的 struct proc 指针。myproc 禁用中断,调用 mycpu,从 struct cpu 中获取当前进程指针(c->proc),然后启用中断。即使启用了中断,myproc 的返回值也是可以安全使用的:如果定时器中断将调用进程移动到不同的 CPU,其 struct proc 指针将保持不变。
Sleep and wakeup
调度和锁有助于将一个线程的操作对其他线程隐藏起来,但我们也需要一些抽象概念来帮助线程有意地进行交互。例如,在 xv6 中,管道的读取者可能需要等待写入进程产生数据;父进程调用等待可能需要等待子进程退出;一个读取磁盘的进程需要等待磁盘硬件完成读取操作。在这些情况(以及许多其他情况)下,xv6 内核使用一种称为睡眠(sleep)和唤醒(wakeup)的机制。
睡眠允许内核线程等待特定事件;另一个线程可以调用唤醒来表示等待事件的线程应该恢复执行。睡眠和唤醒通常被称为顺序协调或条件同步机制。 睡眠和唤醒提供了一个相对低级的同步接口。为了说明它们在 xv6 中的工作方式,我们将使用它们来构建一个更高级的同步机制,称为信号量(semaphore),用于协调生产者和消费者(xv6 并不使用信号量)。信号量维护一个计数,并提供两个操作。“V”操作(针对生产者)会增加计数。“P”操作(针对消费者)会等待直到计数不为零,然后将其减一并返回。如果只有一个生产者线程和一个消费者线程,并且它们在不同的 CPU 上执行,并且编译器没有过度优化,那么这种实现是正确的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23100 struct semaphore {
101 struct spinlock lock;
102 int count;
103 };
104
105 void
106 V(struct semaphore *s)
107 {
108 acquire(&s->lock);
109 s->count += 1;
110 release(&s->lock);
111 }
75
112
113 void
114 P(struct semaphore *s)
115 {
116 while(s->count == 0)
117 ;
118 acquire(&s->lock);
119 s->count -= 1;
120 release(&s->lock);
121 }上述实现的代价是高昂的。如果生产者很少行动,那么消费者将把大部分时间花在 while 循环中,希望计数不为零。相比于通过反复轮询 s->count 进行忙等待,消费者的 CPU 可能会找到更有成效的工作。 避免忙等待需要一种让消费者让出 CPU 并仅在 V 增加计数后恢复的方法。 这是朝这个方向迈出的一步,尽管正如我们将看到的,这还不够。让我们想象一对调用,sleep 和 wakeup,它们的工作方式如下。sleep(chan) 在任意值 chan 上睡眠,chan 被称为等待通道。sleep 使调用进程进入睡眠状态,释放 CPU 以进行其他工作。wakeup(chan) 唤醒所有在 chan 上睡眠的进程(如果有),导致它们的 sleep 调用返回。如果没有进程在 chan 上等待,wakeup 则什么都不做。我们可以改变信号量的实现来使用 sleep 和 wakeup(修改部分以黄色突出显示):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18200 void
201 V(struct semaphore *s)
202 {
203 acquire(&s->lock);
204 s->count += 1;
205 wakeup(s); // HIGH LIGHT
206 release(&s->lock);
207 }
208
209 void
210 P(struct semaphore *s)
211 {
212 while(s->count == 0)
213 sleep(s); // HIGH LIGHT
214 acquire(&s->lock);
215 s->count -= 1;
216 release(&s->lock);
217 }现在 P 会放弃 CPU 而不是忙等待,这很不错。然而,事实证明,使用这种接口设计 sleep 和 wakeup 并非易事,否则会遇到所谓的“丢失唤醒”问题。假设 P 在第 212 行发现 s->count == 0。当 P 处于第 212 行和第 213 行之间时,V 在另一个 CPU 上运行:它将 s->count 更改为非零值并调用 wakeup,但 wakeup 发现没有进程在睡眠,因此什么也不做。现在 P 在第 213 行继续执行:它调用 sleep 并进入睡眠状态。这就导致了一个问题:P 在睡眠中等待一个已经发生过的 V 调用。除非我们运气好,生产者再次调用 V,否则即使计数非零,消费者也会永远等待下去。 这个问题的根源在于,当 V 在错误的时刻运行时,违反了 P 仅在 s->count == 0 时才睡眠的不变性。一种错误的保护该不变性的方法是在 P 中移动获取锁的位置(如下文中以黄色突出显示的部分),以使它对计数的检查和对 sleep 的调用是原子性的:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18300 void
301 V(struct semaphore *s)
302 {
303 acquire(&s->lock);
304 s->count += 1;
305 wakeup(s);
306 release(&s->lock);
307 }
308
309 void
310 P(struct semaphore *s)
311 {
312 acquire(&s->lock); // HIGH LIGHT
313 while(s->count == 0)
314 sleep(s);
315 s->count -= 1;
316 release(&s->lock);
317 }有人可能希望这个版本的 P 能够避免丢失唤醒的情况,因为锁可以防止 V 在第 313 行和第 314 行之间执行。它确实做到了这一点,但同时也导致了死锁:P 在睡眠时持有锁,所以 V 将永远阻塞,等待该锁被释放。 我们将通过改变 sleep 的接口来修复前面的方案:调用者必须将条件锁传递给 sleep,以便在将调用进程标记为睡眠并在睡眠通道上等待后,它可以释放锁。该锁将迫使并发的 V 等待,直到 P 完成自我睡眠,这样唤醒操作就会找到正在睡眠的消费者并将其唤醒。一旦消费者再次被唤醒,sleep 在返回之前会重新获取锁。我们新的正确的 sleep/wakeup 方案可以如下使用(修改部分以黄色突出显示):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18400 void
401 V(struct semaphore *s)
402 {
403 acquire(&s->lock);
404 s->count += 1;
405 wakeup(s);
406 release(&s->lock);
407 }
408
409 void
410 P(struct semaphore *s)
411 {
412 acquire(&s->lock);
413 while(s->count == 0)
414 sleep(s, &s->lock); // HIGH LIGHT
415 s->count -= 1;
416 release(&s->lock);
417 }P 持有 s->lock 这一事实可防止 V 在 P 检查 s->count 与调用 sleep 之间尝试将其唤醒。然而,请注意,为了避免丢失唤醒的情况,我们需要 sleep 原子性地释放s->lock并使消费进程进入睡眠状态。
Code: Sleep and wakeup
Xv6 的 sleep(位于 kernel/proc.c:536)和 wakeup(位于 kernel/proc.c:567)提供了如上述最后一个示例中所示的接口,它们的实现(以及如何使用它们的规则)确保不会出现丢失唤醒的情况。基本思路是让 sleep 将当前进程标记为 SLEEPING,然后调用 sched 来释放 CPU;wakeup 则在给定的等待通道上寻找处于睡眠状态的进程,并将其标记为 RUNNABLE。sleep 和 wakeup 的调用者可以使用任何相互方便的数字作为通道。Xv6 通常使用与等待相关的内核数据结构的地址。
sleep 会获取 p->lock(位于 kernel/proc.c:547)。现在,即将进入睡眠的进程同时持有 p->lock 和 lk。在调用者中(在示例中为 P)持有 lk 是必要的:它确保没有其他进程(在示例中,运行 V 的进程)可以开始调用 wakeup(chan)。现在 sleep 持有 p->lock,那么释放 lk 是安全的:其他一些进程可能会开始调用 wakeup(chan),但 wakeup 将等待获取 p->lock,因此会等到 sleep 完成将进程设置为睡眠状态,从而避免唤醒操作错过睡眠操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27// 原子地释放锁并在 chan 上睡眠。
// 被唤醒时重新获取锁。
void
sleep(void *chan, struct spinlock *lk)
{
struct proc *p = myproc(); // 获取当前进程
// 必须获取 p->lock 才能更改 p->state 并调用 sched。
// 一旦我们持有 p->lock,就可以保证我们不会错过任何唤醒
//(唤醒会锁定 p->lock),
// 因此释放 lk 是安全的。
acquire(&p->lock); // 获取进程的锁
release(lk); // 释放传入的锁
// 进入睡眠状态。
p->chan = chan; // 设置进程的睡眠通道
p->state = SLEEPING; // 设置进程状态为 SLEEPING
sched(); // 调度器函数,切换到其他可运行的进程
// 清理
p->chan = 0; // 清除进程的睡眠通道
// 重新获取原始锁。
release(&p->lock); // 释放进程的锁
acquire(lk); // 获取传入的锁
}现在 sleep 持有 p->lock 且没有其他进程持有,它可以通过记录睡眠通道、将进程状态更改为 SLEEPING 并调用 sched 来使进程进入睡眠状态(位于 kernel/proc.c:551 - 554)。稍后我们会明白,为什么在进程被标记为 SLEEPING 之后才能释放 p->lock(由调度器释放)是至关重要的。
在某个时刻,一个进程会获取条件锁,设置睡眠者正在等待的条件,并调用 wakeup(chan)。重要的是,在持有条件锁的情况下调用 wakeup。wakeup 会遍历进程表(位于 kernel/proc.c:567)。它会获取它检查的每个进程的 p->lock,这既是因为它可能会操作该进程的状态,也是因为 p->lock 可确保 sleep 和 wakeup 不会相互错过。当 wakeup 发现一个处于 SLEEPING 状态且具有匹配 chan 的进程时,它会将该进程的状态更改为 RUNNABLE。下一次调度器运行时,它会发现该进程已准备好运行。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19// 唤醒所有在 chan 上睡眠的进程。
// 必须在没有任何 p->lock 的情况下调用。
void
wakeup(void *chan)
{
struct proc *p;
// 遍历所有进程
for(p = proc; p < &proc[NPROC]; p++) {
if(p!= myproc()){
acquire(&p->lock);
// 如果进程状态为 SLEEPING 且通道与传入的通道相同
if(p->state == SLEEPING && p->chan == chan) {
// 设置进程状态为 RUNNABLE
p->state = RUNNABLE;
}
release(&p->lock);
}
}
}有时会出现多个进程在同一通道上睡眠的情况;例如,多个进程从一个管道中读取数据。一次 wakeup 调用会将它们全部唤醒。其中一个进程会首先运行并获取在 sleep 调用时使用的锁,并且(在管道的情况下)读取管道中等待的任何数据。其他进程会发现,尽管被唤醒,但没有数据可供读取。从它们的角度来看,这次唤醒是“虚假的”,它们必须再次睡眠。因此,sleep 总是在一个检查条件的循环中被调用。
如果 sleep/wakeup 的两次使用偶然选择了相同的通道,也不会造成任何危害:它们会看到虚假唤醒,但如上述所述的循环可以容忍这个问题。sleep/wakeup 的很大魅力在于它既轻量级(无需创建特殊的数据结构来作为睡眠通道),又提供了一层间接性(调用者无需知道他们正在与哪个具体进程进行交互)。
Code: Pipes
一个使用 sleep 和 wakeup 来同步生产者和消费者的更复杂的示例是 xv6 中管道的实现。我们在第 1 章中看到了管道的接口:写入管道一端的字节会被复制到内核缓冲区中,然后可以从管道的另一端读取。后续章节将研究围绕管道的文件描述符支持,但现在我们先来看看 pipewrite 和 piperead 的实现。
每个管道都由一个 struct pipe 表示,其中包含一个锁和一个数据缓冲区。字段 nread 和 nwrite 分别计算从缓冲区读取和写入的字节总数。缓冲区是循环的:在 buf[PIPESIZE - 1]之后写入的下一个字节是 buf[0]。但计数不会循环。这种约定使得实现可以区分满缓冲区(nwrite == nread + PIPESIZE)和空缓冲区(nwrite == nread),但这意味着对缓冲区的索引必须使用 buf[nread % PIPESIZE]而不是仅仅 buf[nread](nwrite 同理)。
1
2
3
4
5
6
7
8struct pipe {
struct spinlock lock;
char data[PIPESIZE];
uint nread; // number of bytes read
uint nwrite; // number of bytes written
int readopen; // read fd is still open
int writeopen; // write fd is still open
};假设在两个不同的 CPU 上同时发生对 piperead 和 pipewrite 的调用。pipewrite(kernel/pipe.c:77)首先获取管道的锁,该锁用于保护计数、数据及其相关的不变量。然后 piperead(kernel/pipe.c:106)也尝试获取该锁,但无法获取。它在 acquire(kernel/spinlock.c:22)中循环等待锁。在 piperead 等待的过程中,pipewrite 循环处理要写入的字节(addr[0..n - 1]),依次将每个字节添加到管道中(kernel/pipe.c:95)。在这个循环中,可能会出现缓冲区已满的情况(kernel/pipe.c:88)。在这种情况下,pipewrite 调用 wakeup 以提醒任何正在睡眠的读取者缓冲区中有数据等待,然后在 &pi->nwrite 上睡眠,等待读取者从缓冲区中取出一些字节。sleep 在将 pipewrite 的进程置于睡眠状态时会释放 pi->lock。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70int
pipewrite(struct pipe *pi, uint64 addr, int n)
{
// 这里的i为写入的字节数
int i = 0;
struct proc *pr = myproc();
acquire(&pi->lock);
// 当写入的字节数小于n时
while(i < n){
// 如果管道的读端未打开或进程被杀死
if(pi->readopen == 0 || killed(pr)){
release(&pi->lock);
return -1;
}
// 如果管道已满
if(pi->nwrite == pi->nread + PIPESIZE){
wakeup(&pi->nread); // 唤醒等待读的进程
sleep(&pi->nwrite, &pi->lock); // 使当前进程睡眠等待写入空间
}
// 管道未满
else {
char ch;
// 从用户空间复制一个字节到内核空间
if(copyin(pr->pagetable, &ch, addr + i, 1) == -1)
break;
pi->data[pi->nwrite++ % PIPESIZE] = ch; // 将字符写入管道
i++; // 写入的字节数加 1
}
}
// 唤醒等待读的进程
wakeup(&pi->nread);
release(&pi->lock);
// 返回写入的字节数
return i;
}
int
piperead(struct pipe *pi, uint64 addr, int n)
{
int i;
struct proc *pr = myproc();
char ch;
acquire(&pi->lock);
// 当管道为空且写端未关闭时
while(pi->nread == pi->nwrite && pi->writeopen){
// 如果进程被杀死
if(killed(pr)){
release(&pi->lock);
return -1;
}
// 使当前进程睡眠等待数据
sleep(&pi->nread, &pi->lock);
}
// 当读取的字节数小于n时
for(i = 0; i < n; i++){
// 如果管道为空
if(pi->nread == pi->nwrite)
break; // 退出循环
// 从管道读取一个字节并复制到用户空间
ch = pi->data[pi->nread++ % PIPESIZE];
if(copyout(pr->pagetable, addr + i, &ch, 1) == -1)
break;
}
// 唤醒等待写的进程
wakeup(&pi->nwrite);
release(&pi->lock);
// 返回读取的字节数
return i;
}管道代码为读取者和写入者使用了单独的睡眠通道(pi->nread 和 pi->nwrite);在不太可能出现的有大量读取者和写入者等待同一个管道的情况下,这可能会使系统更高效。管道代码在一个检查睡眠条件的循环内进行睡眠;如果有多个读取者或写入者,除了第一个被唤醒的进程外,其他所有进程都会发现条件仍然为假并再次睡眠。
Code: Wait, exit, and kill
sleep 和 wakeup 可用于多种等待情况。一个有趣的例子是子进程的退出与父进程的等待之间的交互。在子进程终止时,父进程可能已经在 wait 中睡眠,或者可能在做其他事情;在后一种情况下,后续的 wait 调用必须能够察觉到子进程的终止,这可能是在子进程调用 exit 很久之后。xv6 记录子进程终止状态直至 wait 察觉到的方式是,让 exit 将调用者置为 ZOMBIE 状态,子进程会保持该状态,直到父进程的 wait 注意到它,将子进程的状态更改为 UNUSED,复制子进程的退出状态,并将子进程的进程 ID 返回给父进程。如果父进程在子进程之前退出,父进程会将子进程交给 init 进程,init 进程会不断地调用 wait;因此,每个子进程都有一个父进程来进行清理。一个问题是要避免同时发生的父进程与子进程的 wait 和 exit 之间以及同时发生的 exit 之间出现竞争条件和死锁。
wait 从获取 wait_lock 开始(kernel/proc.c:391)。原因是 wait_lock 作为条件锁,有助于确保父进程不会错过退出子进程的唤醒信号。然后 wait 扫描进程表。如果它发现一个处于 ZOMBIE 状态的子进程,它会释放该子进程的资源和其proc结构,将子进程的退出状态复制到提供给 wait 的地址(如果该地址不为 0),并返回子进程的进程 ID。如果 wait 找到了子进程,但没有一个已经退出,它会调用 sleep 等待它们中的任何一个退出,然后再次扫描。wait 通常持有两个锁,wait_lock 和某个进程的 pp->lock;避免死锁的顺序是先获取 wait_lock,然后获取 pp->lock。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52// 等待子进程退出并返回其pid
// 如果此进程没有子进程,则返回-1
int
wait(uint64 addr)
{
struct proc *pp;
int havekids, pid;
struct proc *p = myproc();
acquire(&wait_lock);
for(;;){ // 无限循环
// 扫描进程表,寻找已退出的子进程
// 初始化 havekids为0
havekids = 0;
// 遍历进程表
for(pp = proc; pp < &proc[NPROC]; pp++){
// 如果找到子进程
if(pp->parent == p){
// 确保子进程不在exit()或swtch()中,获取子进程的锁
acquire(&pp->lock);
// 设置 havekids 为 1,表示找到子进程
havekids = 1;
// 如果子进程状态为 ZOMBIE(已退出)
if(pp->state == ZOMBIE){
// 找到一个已退出的子进程。
pid = pp->pid; // 获取子进程的 PID
// 如果需要将子进程的状态复制到指定地址
if(addr!= 0 && copyout(p->pagetable, addr, (char *)&pp->xstate,
sizeof(pp->xstate)) < 0) {
// 释放等待锁和子进程的锁并返回-1以表示失败
release(&pp->lock);
release(&wait_lock);
return -1;
}
// 释放子进程的资源以及相关的锁,返回pid表示成功
freeproc(pp);
release(&pp->lock);
release(&wait_lock);
return pid;
}
// 如果子进程状态不为ZOMBIE,直接释放子进程的锁
release(&pp->lock);
}
}
// 如果没有子进程或当前进程被杀死,则无需等待
if(!havekids || killed(p)){
release(&wait_lock);
return -1;
}
// 否则我们先等待子进程退出,使父进程进入睡眠状态
sleep(p, &wait_lock);
}
}exit(kernel/proc.c:347)记录退出状态,释放一些资源,调用 reparent 将其子女交给 init 进程,在父进程处于 wait 状态时唤醒它,将调用者标记为僵尸进程,并永久让出 CPU。在这个过程中,exit 同时持有 wait_lock 和 p->lock。它持有 wait_lock 是因为它是 wakeup(p->parent)的条件锁,防止处于 wait 状态的父进程丢失唤醒信号。exit 在此过程中也必须持有 p->lock,以防止处于 wait 状态的父进程在子进程最终调用 swtch 之前看到子进程处于 ZOMBIE 状态。exit 以与 wait 相同的顺序获取这些锁,以避免死锁。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42// 退出当前进程。不会返回
// 已退出的进程将保持僵尸状态,直到其父进程调用 wait()
void
exit(int status)
{
struct proc *p = myproc();
// 如果当前进程是初始化进程则触发panic
// 这么做的原因是初始化的进程不应退出
if(p == initproc)
panic("init exiting");
// 关闭所有打开的文件,遍历所有文件描述符
for(int fd = 0; fd < NOFILE; fd++){
// 如果文件描述符对应的文件存在,就获取其指针并关闭文件
if(p->ofile[fd]){
struct file *f = p->ofile[fd];
fileclose(f);
// 将文件描述符设置为 0,表示文件已关闭
p->ofile[fd] = 0;
}
}
// 涉及文件操作,暂时不管
begin_op();
iput(p->cwd);
end_op();
p->cwd = 0;
acquire(&wait_lock);
// 将所有子进程交给初始化进程,重新设置父进程
reparent(p);
// 父进程可能正在 wait() 中睡眠,所以唤醒父进程
wakeup(p->parent);
acquire(&p->lock);
// 设置进程的退出状态
p->xstate = status;
// 将进程状态设置为僵尸状态
p->state = ZOMBIE;
release(&wait_lock);
// 跳转到调度器,切换到其它进程
sched();
// 这里panic的原因是,上面调用sched后会切换到别的进程
// 不会返回继续执行,如果进程执行到了这里,就说明出现错误
panic("zombie exit");
}exit 在将自身状态设置为 ZOMBIE 之前就唤醒父进程,这看起来可能不正确,但实际上是安全的:尽管 wakeup 可能会导致父进程运行,但 wait 中的循环在调度器释放子进程的 p->lock 之前无法检查子进程,所以 wait 要在 exit 将其状态设置为 ZOMBIE 之后很久才能查看正在退出的进程(kernel/proc.c:379)。
虽然 exit 允许一个进程自行终止,但 kill(kernel/proc.c:586)允许一个进程请求另一个进程终止。如果 kill 直接销毁目标进程,那会过于复杂,因为目标进程可能正在另一个 CPU 上执行,也许正在对内核数据结构进行一系列敏感更新的过程中。因此,kill 所做的非常少:它只是设置目标进程的 p->killed,如果目标进程正在睡眠,就将其唤醒。最终,目标进程会进入或离开内核,此时 usertrap 中的代码会在 p->killed 被设置的情况下调用 exit(它通过调用 killed(kernel/proc.c:615)来检查)。如果目标进程在用户空间中运行,它很快就会通过进行系统调用或因为定时器(或其他一些设备)中断而进入内核。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26// 杀死指定pid的进程
// 被杀死的进程直到尝试返回用户空间(见trap.c中的usertrap())才会退出。
int
kill(int pid)
{
struct proc *p;
// 遍历进程
for(p = proc; p < &proc[NPROC]; p++){
acquire(&p->lock);
// 如果遍历到pid为要求的进程
if(p->pid == pid){
// 将进程标记为已杀死
p->killed = 1;
// 如果进程处于睡眠状态
if(p->state == SLEEPING){
// 将进程状态设置为可运行
p->state = RUNNABLE;
}
release(&p->lock); // 释放进程的锁
return 0;
}
release(&p->lock);
}
// 遍历没发现pid符合的进程返回-1
return -1;
}如果目标进程正在睡眠,kill 对 wakeup 的调用会导致目标进程从睡眠中返回。这可能是危险的,因为正在等待的条件可能不再为真。然而,xv6 中对 sleep 的调用总是被包裹在一个 while 循环中,在 sleep 返回后会重新测试条件。一些对 sleep 的调用在循环中也会检查 p->killed,如果被设置,就放弃当前活动。只有在这种放弃是正确的情况下才会这样做。例如,如果设置了 killed 标志,管道读和写代码会返回;最终,代码会返回到 trap,trap 会再次检查 p->killed 并退出。
一些 xv6 的 sleep 循环不会检查 p->killed,因为代码处于一个应该是原子性的多步骤系统调用的中间。virtio 驱动程序(kernel/virtio_disk.c:285)就是一个例子:它不会检查 p->killed,因为磁盘操作可能是一系列写入操作中的一个,为了使文件系统处于正确的状态,所有这些写入操作都是必需的。一个在等待磁盘 I/O 时被杀死的进程,在完成当前系统调用且 usertrap 看到 killed 标志之前不会退出。
Process Locking
与每个进程相关联的锁(p->lock)是 xv6 中最复杂的锁。简单地理解 p->lock,可以认为在读取或写入以下任何一个 struct proc 字段时必须持有该锁:p->state、p->chan、p->killed、p->xstate 和 p->pid。这些字段可能会被其他进程或其他核心上的调度器线程使用,因此它们必须由锁来保护是很自然的。 然而,p->lock 的大多数使用是为了保护 xv6 进程数据结构和算法的更高级方面。以下是 p->lock 所做的全部事情:
• 与 p->state 一起,它防止在为新进程分配 proc 槽位时出现竞争。
• 在一个进程被创建或销毁时,它将该进程隐藏起来,使其不被看到。
• 它防止父进程的 wait 收集一个已将其状态设置为 ZOMBIE 但尚未让出 CPU 的进程。
• 它防止在一个进程将其状态设置为 RUNNABLE 但在完成 swtch 之前,另一个核心的调度器决定运行该正在让出的进程。
• 它确保只有一个核心的调度器决定运行一个可运行(RUNNABLE)的进程。
• 它防止在进程处于 swtch 过程中时,定时器中断导致该进程让出。
• 与条件锁一起,它有助于防止 wakeup 忽略一个正在调用 sleep 但尚未完成让出 CPU 的进程。
• 它防止被 kill 的进程在 kill 检查 p->pid 与设置 p->killed 之间退出并可能被重新分配。
• 它使 kill 对 p->state 的检查和写入具有原子性。
p->parent 字段由全局锁 wait_lock 而非 p->lock 来保护。只有一个进程的父进程会修改 p->parent,不过该字段会被进程自身以及其他寻找其子女的进程读取。wait_lock 的目的是在 wait 睡眠等待任何子进程退出时充当条件锁。一个正在退出的子进程会持有 wait_lock 或 p->lock,直到它将自己的状态设置为 ZOMBIE,唤醒其父进程,并让出 CPU 之后。wait_lock 还会对父进程和子进程的并发退出进行串行化,以确保 init 进程(它继承了子进程)一定会从其等待中被唤醒。wait_lock 是一个全局锁,而不是每个父进程中的每个进程锁,因为在一个进程获取它之前,它无法知道自己的父进程是谁。
实际情况
xv6 调度器实现了一种简单的调度策略,即依次运行每个进程。这种策略被称为轮询调度。真正的操作系统会实现更复杂的策略,例如,允许进程具有优先级。其理念是,调度器会优先选择可运行的高优先级进程,而不是可运行的低优先级进程。这些策略可能会很快变得复杂,因为往往存在相互竞争的目标:例如,操作系统可能还希望保证公平性和高吞吐量。此外,复杂的策略可能会导致意想不到的交互,如优先级反转和护航现象。当低优先级和高优先级进程都使用特定的锁时,可能会发生优先级反转,当低优先级进程获取该锁时,会阻止高优先级进程取得进展。当许多高优先级进程在等待一个获取共享锁的低优先级进程时,可能会形成一个长时间等待的进程护航队列;一旦护航队列形成,它可能会持续很长时间。为了避免这些问题,复杂的调度器中需要额外的机制。
睡眠(sleep)和唤醒(wakeup)是一种简单而有效的同步方法,但还有许多其他方法。所有这些方法面临的第一个挑战是避免我们在本章开头看到的“丢失唤醒”问题。原始的 Unix 内核的睡眠操作只是简单地禁用中断,这在 Unix 运行在单 CPU 系统上时是足够的,因为在这种系统中只有一个 CPU 执行操作。由于 xv6 运行在多处理器上,所以它在睡眠操作中添加了一个显式的锁。
在唤醒操作中扫描整个进程集是低效的。一个更好的解决方案是将睡眠和唤醒中的通道(chan)替换为一个数据结构,该数据结构保存了在该结构上睡眠的进程列表,例如 Linux 的等待队列。许多线程库将相同的结构称为条件变量(condition variable);在这种情况下,睡眠和唤醒操作分别称为等待(wait)和通知(signal)。所有这些机制都有相同的特点:睡眠条件由某种在睡眠期间以原子方式释放的锁来保护。
唤醒操作的实现会唤醒所有在特定通道上等待的进程,可能有许多进程在等待该特定通道。操作系统会调度所有这些进程,它们会竞相检查睡眠条件。以这种方式运行的进程有时被称为惊群(thundering herd),最好避免这种情况。大多数条件变量有两个用于唤醒的原语:通知(signal),它唤醒一个进程;广播(broadcast),它唤醒所有等待的进程。
信号量(Semaphores)常用于同步。计数通常对应于诸如管道缓冲区中可用的字节数或一个进程拥有的僵尸子进程的数量等。将显式计数作为抽象的一部分,可以避免“丢失唤醒”问题:有一个对已发生的唤醒次数的显式计数。该计数还可以避免虚假唤醒和惊群问题。
在 xv6 中,终止进程并进行清理会引入很多复杂性。在大多数操作系统中,这甚至更加复杂,例如,被终止的进程可能在内核深处睡眠,展开其栈需要小心处理,因为调用栈上的每个函数可能都需要进行一些清理工作。一些语言通过提供异常机制来提供帮助,但 C 语言没有。此外,还有其他事件可能导致一个睡眠进程被唤醒,即使它所等待的事件尚未发生。例如,当一个 Unix 进程正在睡眠时,另一个进程可能向它发送一个信号。在这种情况下,该进程将从被中断的系统调用中返回,值为 -1,错误代码设置为 EINTR。应用程序可以检查这些值并决定如何处理。xv6 不支持信号,因此不会出现这种复杂性。
一个真正的操作系统会使用一个显式的空闲列表在常数时间内找到空闲的进程结构,而不是像 allocproc 中那样进行线性时间的搜索;xv6 为了简单起见使用了线性扫描。
1. Uthread: switching between threads ()
为用户级线程系统设计上下文切换机制并实现。当前分支xv6有两个文件 user/uthread.c 和 user/uthread_switch.S,以及 Makefile 中的一个规则来构建 uthread 程序。uthread.c 包含了大部分用户级线程包,以及三个简单测试线程的代码。线程包缺少一些创建线程和在线程之间切换的代码。设计并实现一个创建线程并保存/恢复寄存器以在线程之间切换的计划。
在 user/uthread.c 中的 thread_create()和 thread_schedule()以及 user/uthread_switch.S 中的 thread_switch 中添加代码。一个目标是确保当 。另一个目标是确保 thread_switch 保存正在切换的线程的寄存器,恢复正在切换到的线程的寄存器,并返回到后一个线程的指令中上次停止的位置。你将不得不决定在哪里保存/恢复寄存器;修改 struct thread 来保存寄存器是一个好的计划。你需要在 thread_schedule 中添加对 thread_switch 的调用;你可以向 thread_switch 传递你需要的任何参数,但目的是从线程 t 切换到 next_thread。
根据实验提示,需要参考之前内核中的swtch以及线程切换流程,修改 thread_create()和 thread_schedule()两个方法以及 user/uthread_switch.S 来保存寄存器。 修改正确后三个线程将轮流输出0到99并正确结束。
先给struct thread加上寄存器相关的字段来保存寄存器,和上面提到的struct context字段相同即可(可以直接添加头文件到这里直接调用struct context):
1 | |
从main函数开始一步步看代码的逻辑,先是初始化线程启动的标志和线程调用的次数为0,之后调用init初始化第一个进程,然后调用 thread_create(void (*func)()) ,通过传入指向函数的指针作为参数创建a,b,c三个线程。这里需要我们编写代码,根据题目要求和提示,这里不直接调用函数,而是要在 thread_schedule() 第一次运行给定的线程时,该线程在自己的堆栈上执行传递给 thread_create()的函数,ra 寄存器用于保存函数调用返回地址,切换完上下文后会继续执行 ra 寄存器中的函数,而 sp 寄存器用于保存栈地址。
1 | |
thread_switch 只需要保存/恢复被调用者保存的寄存器。
1 | |
除此之外就是修改 thread_schedule()函数,这个函数找到空闲的线程并切换,我们要在这里添加一行代码,去调用thread_switch()。
1 | |
运行截屏:
2. Using threads ()
使用哈希表来探索线程和锁的并行编程。这个实验使用了 UNIX pthread 线程库。你可以从手册页中找到关于它的信息,使用 man pthreads,包括A, B, C。
文件 notxv6/ph.c 包含一个简单的哈希表,如果从单个线程使用它是正确的,但从多个线程使用它是不正确的。在 xv6 目录中,输入以下内容: $ make ph $./ph 1 ,请注意,为了构建 ph,Makefile 使用了你操作系统的 gcc,而不是 6.1810 工具。ph 的参数指定了在哈希表上执行 put 和 get 操作的线程数。ph 运行两个基准测试。首先,它通过调用 put()向哈希表中添加大量键,并打印每秒的插入速率。然后,它使用 get()从哈希表中获取键。它打印由于插入而应该在哈希表中但缺失的键的数量(在这种情况下为零),并打印它每秒实现的获取次数。
你可以通过给 ph 一个大于 1 的参数来告诉它从多个线程同时使用其哈希表。
1 | |
这个 ph 2 输出的第一行表明,当两个线程同时向哈希表中添加条目时,它们总共实现了每秒 53044 次插入。这大约是运行 ph 1 的单个线程的两倍。这是一个极好的“并行加速”,大约是人们可能希望的两倍。与此同时,16579 个键缺失的输出表明,本来应该在哈希表中的大量键丢失。也就是说,插入操作应该将这些键添加到哈希表中,但出了问题。查看 notxv6/ph.c,特别是 put()和 insert()。 为什么在 2 个线程时会有缺失的键,而在 1 个线程时不会?确定一个 2 个线程的事件序列,该序列可能导致键缺失。在 answers-thread.txt 中提交你的序列和简短解释。
为了避免这种事件序列,在 notxv6/ph.c 的 put 和 get 中插入 lock 和 unlock 语句,以使两个线程时缺失的键的数量始终为 0。相关的 pthread 调用是:
1 | |
阅读了 notxv6/ph.c,这段代码的主要功能是在多线程环境下对哈希表进行插入和获取操作,并统计操作的时间和性能。只需要给 put 加锁即可解决由多线程并发导致的键值缺失问题。
1 | |
3. Barrier()
本实验将实现一个 Barrier(屏障) :应用程序中的一个点,所有参与的线程都必须等待,直到所有其他参与的线程也到达该点。将使用 pthread 条件变量,这是一种类似于 xv6 的 sleep 和 wakeup 的序列协调技术。文件 notxv6/barrier.c 包含一个损坏的屏障。
1 | |
2 指定了在屏障上同步的线程数量(barrier.c 中的 nthread)。每个线程执行一个循环,在每个循环迭代中,线程调用 barrier(),然后睡眠一段随机数量的微秒。断言触发,因为一个线程在另一个线程到达屏障之前离开了屏障。期望的行为是每个线程在 barrier()中阻塞,直到所有 nthreads 个线程都调用了 barrier()。 参考文档A , B。
1 | |
pthread_cond_wait 在调用时释放 mutex,并在返回之前重新获取 mutex。 目前已经存在 barrier_init(),还需要完成的工作是实现 barrier(),以使 panic 不会发生。已经定义了 struct barrier 用于完成, 有两个问题使任务复杂化: 必须处理一系列的屏障调用,将每个调用称为一轮。bstate.round 记录当前轮次。应该在所有线程都到达屏障时递增 bstate.round。 必须处理一个线程在其他线程还没有退出屏障时就绕过循环的情况。特别是,你正在从一轮到下一轮重复使用 bstate.nthread 变量。确保离开屏障并绕过循环的线程不会在仍在使用它的前一轮增加 bstate.nthread。
具体实现简单来说就是每有一个进程运行了barrier函数,就让到达线程数量加1并判断是否等于总线程数量,不等于之前就一直等待,相等之后就唤醒等待的所有线程即可。
1 | |
运行打分脚本结果(虚拟机和用户名更改为monika):
七、Lab7: Networking
完成实验之前,首先阅读xv6文档的Chapter 5: Interrupts and device drivers部分,以下是这部分的主要内容:
驱动程序是操作系统中管理特定设备的代码,它配置设备硬件,处理中断,并与进程交互。设备通常可以生成中断,内核陷阱处理代码会识别并调用驱动程序的中断处理程序。许多设备驱动程序在两个上下文中执行代码:上半部在进程的内核线程中运行,通过系统调用要求设备执行 I/O,并等待操作完成;下半部在中断时执行,找出已完成的操作,唤醒等待的进程,并告诉硬件开始处理下一个操作。内核陷阱处理代码识别设备何时发出中断并调用驱动程序的中断处理程序;在 xv6 中,这种调度发生在 devintr(kernel/trap.c:178)中。
1 | |
控制台输入
控制台驱动程序(kernel/console.c)是驱动程序结构的一个简单示例。控制台驱动程序通过连接到 RISC-V 的 UART 串行端口硬件接受人类输入的字符。用户进程,如 shell,使用 read 系统调用从控制台获取输入行。当 QEMU 向 xv6 输入时,按键通过 QEMU 模拟的 UART 硬件传递给 xv6。
UART 硬件对软件来说是一组内存映射的控制寄存器。也就是说,有一些物理地址, RISC-V 硬件将其连接到 UART 设备,因此加载和存储与设备硬件而不是 RAM 进行交互。UART 的内存映射地址从 0x10000000 开始,即 UART0(kernel/memlayout.h:21)。有一些 UART 控制寄存器,每个寄存器的宽度为一个字节。它们相对于 UART0 的偏移量在(kernel/uart.c:22)中定义。例如,LSR 寄存器包含指示输入字符是否等待软件读取的位。这些字符(如果有)可从 RHR 寄存器读取。每次读取一个字符时,UART 硬件将其从等待字符的内部 FIFO 中删除,并在 FIFO 为空时清除 LSR 中的“就绪”位。UART 发送硬件在很大程度上独立于接收硬件;如果软件向 THR 写入一个字节,UART 将发送该字节。
接下来将按照官方文档和其对应代码对控制台产生中断的过程进行解释,Xv6 的 main 函数调用 consoleinit(kernel/console.c:182)来初始化 UART 硬件。该代码将 UART 配置为在接收每个输入字节时生成接收中断,并在每次 UART 完成发送一个输出字节时生成发送完成中断(kernel/uart.c:53)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34// kernel/console.c:182
void consoleinit(void)
{
initlock(&cons.lock, "cons");
// 初始化 UART
uartinit();
// 将读和写系统调用与consoleread和consolewrite函数连接起来
devsw[CONSOLE].read = consoleread;
devsw[CONSOLE].write = consolewrite;
}
// kernel/uart.c:53
void uartinit(void)
{
// IER:interrupt enable register
// 禁用中断
WriteReg(IER, 0x00);
// LCR_BAUD_LATCH:(1<<7),special mode to set baud rate
// 设置波特率的特殊模式
WriteReg(LCR, LCR_BAUD_LATCH);
// 波特率为38.4K的最低有效位
WriteReg(0, 0x03);
// 波特率为38.4K的最高有效位
WriteReg(1, 0x00);
// 离开设置波特率模式,
// 并将字长设置为 8 位,无奇偶校验
WriteReg(LCR, LCR_EIGHT_BITS);
// 重置并启用 FIFO(先进先出缓冲区)
WriteReg(FCR, FCR_FIFO_ENABLE | FCR_FIFO_CLEAR);
// 启用发送和接收中断
WriteReg(IER, IER_TX_ENABLE | IER_RX_ENABLE);
// 初始化锁
initlock(&uart_tx_lock, "uart");
}xv6 shell 通过 init.c 打开的文件描述符从控制台读取(user/init.c:19)。对 read 系统调用的调用通过内核到达 consoleread(kernel/console.c:80)。consoleread 等待输入到达(通过中断)并缓冲在 cons.buf 中,将输入复制到用户空间,并在收到整行后返回用户进程。如果用户尚未输入完整的一行,任何读取进程将在 sleep 调用中等待。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47// kernel/console.c:80
// 用户从控制台读取的内容将在这里处理
// 将(最多)一整行输入复制到dst中
// user_dst指示dst是用户地址还是内核地址
int
consoleread(int user_dst, uint64 dst, int n)
{
uint target; // 目标要读取的字节数
int c; // 从缓冲区中获取的字符
char cbuf; // 用于复制到用户空间缓冲区的字符
target = n;
acquire(&cons.lock);
// 等待中断处理程序填充缓冲区
while(n > 0){
// 控制台缓冲区为空时如果进程未被killed就进入sleep等待
while(cons.r == cons.w){
if(killed(myproc())){
release(&cons.lock);
return -1;
}
sleep(&cons.r, &cons.lock);
}
// 存在输入时获取输入的字符
c = cons.buf[cons.r++ % INPUT_BUF_SIZE];
// 如果读取到文件结束符
if(c == C('D')){
// 如果已经读取的字节数小于目标字节数,将文件结束符保留在缓冲区中
if(n < target){
cons.r--;
}
break;
}
// 将读取的字符复制到用户空间缓冲区
cbuf = c;
if(either_copyout(user_dst, dst, &cbuf, 1) == -1)
break;
dst++;
--n;
// 读到换行符,说明读完一行了,返回用户级别的读取函数
if(c == '\n'){
break;
}
}
release(&cons.lock);
// 最后返回的是实际读取的字符数量
return target - n;
}当用户输入一个字符时,UART 硬件请求 RISC-V 引发中断,从而激活 xv6 的陷阱处理程序,调用 devintr(kernel/trap.c:178),它查看 RISC-V scause 寄存器以发现中断来自外部设备。然后它请求一个称为 PLIC 的硬件单元告诉它哪个设备中断(kernel/trap.c:187)。如果是 UART,devintr 调用 uartintr。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68// 处理 UART 中断,从上方代码块中的devintr()调用
void uartintr(void)
{
// 读取并处理传入的字符。
while (1)
{
int c = uartgetc(); // 从 UART 获取一个字符
// 如果没有字符可读,退出循环
if (c == -1)
break;
consoleintr(c); // 处理获取到的字符
}
// 发送缓冲的字符。
acquire(&uart_tx_lock);
uartstart();
release(&uart_tx_lock);
}
// 控制台输入中断处理程序
// uartintr()有输入字符时调用此函数
// 进行删除/擦除处理,将字符附加到 cons.buf 中
// 如果整行已到达,则唤醒 consoleread()
// 这是会对每一个字符都进行判定的
void consoleintr(int c)
{
acquire(&cons.lock);
switch (c)
{
// 这里还需要之后学习理解
case C('P'): // 打印进程列表
procdump();
break;
case C('U'): // 杀死当前行
while (cons.e!= cons.w && cons.buf[(cons.e - 1) % INPUT_BUF_SIZE]!= '\n')
{
cons.e--;
consputc(BACKSPACE);
}
break;
case C('H'): // 退格键
case '\x7f': // 删除键
if (cons.e!= cons.w)
{
cons.e--;
consputc(BACKSPACE);
}
break;
default:
if (c!= 0 && cons.e - cons.r < INPUT_BUF_SIZE)
{
// 如果输入的字符是回车就转换成换行符,否则不变
c = (c == '\r')? '\n' : c;
// 将字符展示给用户
consputc(c);
// 将字符存储到cons.buf中
cons.buf[cons.e++ % INPUT_BUF_SIZE] = c;
// 如果读取到完整行(或文件结束),则调用consoleread()
if (c == '\n' || c == C('D') || cons.e - cons.r == INPUT_BUF_SIZE)
{
cons.w = cons.e;
wakeup(&cons.r);
}
}
break;
}
release(&cons.lock);
}uartintr(kernel/uart.c:176)从 UART 硬件读取任何等待的输入字符并将它们交给 consoleintr(kernel/console.c:136);它不等待字符,因为未来的输入将引发新的中断。consoleintr 的任务是在 cons.buf 中累积输入字符,直到收到整行。consoleintr 对退格和其他一些字符进行特殊处理。当收到换行符时,consoleintr 唤醒等待的 consoleread(如果有)。 一旦被唤醒,consoleread 将在 cons.buf 中观察到完整的一行,将其复制到用户空间,并通过系统调用机制返回到用户空间。
控制台输出
对连接到控制台的文件描述符的写系统调用最终到达 uartputc(kernel/uart.c:87)。设备驱动程序维护一个输出缓冲区(uart_tx_buf),以便写入进程不必等待 UART 完成发送;相反,uartputc 将每个字符附加到缓冲区,调用 uartstart 启动设备传输(如果尚未启动),然后返回。uartputc 等待的唯一情况是缓冲区已满。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25// 将一个字符添加到输出缓冲区,并告诉UART如果尚未开始发送则开始发送
// 如果输出缓冲区已满,则阻塞
// 由于它可能阻塞,因此不能从中断中调用
// 它仅适用于write()使用
void uartputc(int c)
{
acquire(&uart_tx_lock);
// 如果处于panic状态,则无限循环
if(panicked){
for(;;)
;
}
// 当发送缓冲区已满时,等待uartstart()释放空间
while (uart_tx_w == uart_tx_r + UART_TX_BUF_SIZE)
{
sleep(&uart_tx_r, &uart_tx_lock);
}
// 将字符添加到发送缓冲区
uart_tx_buf[uart_tx_w % UART_TX_BUF_SIZE] = c;
uart_tx_w += 1;
// 启动UART
uartstart();
release(&uart_tx_lock);
}每次 UART 完成发送一个字节时,它都会产生一个中断。uartintr 调用 uartstart,它检查设备是否真的完成了发送,并将下一个缓冲的输出字符交给设备。因此,如果一个进程向控制台写入多个字节,通常第一个字节将由 uartputc 对 uartstart 的调用发送,而其余缓冲的字节将由 uartintr 随着发送完成中断的到达而调用 uartstart 发送。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26// 如果 UART 处于空闲状态,并且发送缓冲区中有字符等待发送,则发送该字符
// 调用者必须持有 uart_tx_lock。
// 从顶部和底部的一半都可以调用。
void uartstart()
{
while (1)
{
if (uart_tx_w == uart_tx_r)
{
// 发送缓冲区为空。
return;
}
if ((ReadReg(LSR) & LSR_TX_IDLE) == 0)
{
// UART 发送保持寄存器已满
// 因此我们不能再给它一个字节
// 它准备好接收新字节时会中断
return;
}
int c = uart_tx_buf[uart_tx_r % UART_TX_BUF_SIZE];
uart_tx_r += 1;
// 可能 uartputc() 正在等待缓冲区中的空间。
wakeup(&uart_tx_r);
WriteReg(THR, c);
}
}需要注意的一般模式是通过缓冲和中断将设备活动与进程活动解耦。即使没有进程等待读取输入,控制台驱动程序也可以处理输入;后续的读取将看到输入。同样,进程可以发送输出而不必等待设备。这种解耦可以通过允许进程与设备 I/O 并发执行来提高性能,并且在设备速度较慢(如 UART)或需要立即关注(如回显输入的字符)时特别重要。这个想法有时被称为 I/O 并发性。
驱动程序中的并发性和定时器中断
在 consoleread 和 consoleintr 中调用了 acquire,这些调用获取锁,该锁保护控制台驱动程序的数据结构免受并发访问。这里存在三个并发危险:不同 CPU 上的两个进程可能同时调用 consoleread;硬件可能在 CPU 已经在 consoleread 内部执行时请求该 CPU 传递控制台(实际上是 UART)中断;并且硬件可能在 consoleread 执行时在不同的 CPU 上传递控制台中断。这些危险可能导致竞争条件或死锁。驱动程序中需要注意并发的另一种方式是,一个进程可能正在等待来自设备的输入,但是表示输入到达的中断信号可能在不同的进程(或根本没有进程)运行时到达。因此,中断处理程序不允许考虑它们中断的进程或代码。例如,中断处理程序不能安全地使用当前进程的页表调用 copyout。中断处理程序通常执行相对较少的工作(例如,仅将输入数据复制到缓冲区),并唤醒上半部代码来完成其余工作。
Xv6 使用定时器中断来维护其时钟,并使其能够在计算密集型进程之间切换;usertrap 和 kerneltrap 中的 yield 调用会导致这种切换。定时器中断来自连接到每个 RISC-V CPU 的时钟硬件。Xv6 对该时钟硬件进行编程,使其定期中断每个 CPU。RISC-V 要求定时器中断在机器模式下而不是在监督模式下处理。RISC-V 机器模式在没有分页的情况下执行,并且具有一组单独的控制寄存器,因此在机器模式下运行普通的 xv6 内核代码是不实际的。因此,Xv6 完全独立于上述陷阱机制来处理定时器中断。
在 start.c 中机器模式下执行的代码,在 main 之前,设置为接收定时器中断(kernel/start.c:63)。部分工作是对 CLINT 硬件(核心本地中断器)进行编程,使其在一定延迟后产生中断。另一部分是设置一个类似于陷阱帧的暂存区,以帮助定时器中断处理程序保存寄存器和 CLINT 寄存器的地址。最后,start 将 mtvec 设置为 timervec 并启用定时器中断。
当用户或内核代码执行时,定时器中断可以在任何时候发生;内核无法在关键操作期间禁用定时器中断。因此,定时器中断处理程序必须以一种保证不会干扰中断的内核代码的方式完成其工作。基本策略是让处理程序请求 RISC-V 引发“软件中断”并立即返回。RISC-V 使用普通的陷阱机制将软件中断传递给内核,并允许内核禁用它们。可以在 devintr(kernel/trap.c:205)中看到处理定时器中断产生的软件中断的代码。机器模式下的定时器中断处理程序是 timervec(kernel/kernelvec.S:95)。它在 start 准备的暂存区中保存了一些寄存器,告诉 CLINT 何时产生下一个定时器中断,请求 RISC-V 引发软件中断,恢复寄存器,然后返回。定时器中断处理程序中没有 C 代码。
真实情况
Xv6 允许在内核执行时以及在执行用户程序时进行设备和定时器中断。定时器中断会强制从定时器中断处理程序进行线程切换(调用 yield),即使在内核执行时也是如此。如果内核线程有时会花费大量时间计算而不返回用户空间,则在 CPU 内核线程之间公平地进行时间片切换的能力是有用的。如果设备和定时器中断仅在执行用户代码时发生,则内核可以变得稍微简单一些。
在典型的计算机上支持所有设备的完整功能是一项非常艰巨的工作,因为设备数量众多,设备具有许多功能,并且设备与驱动程序之间的协议可能很复杂且文档记录不完善。在许多操作系统中,驱动程序所占用的代码量比核心内核还要多。
UART 驱动程序通过读取 UART 控制寄存器一次检索一个字节的数据;这种模式称为编程 I/O,因为软件正在驱动数据移动。编程 I/O 很简单,但在数据传输速率较高时速度太慢而无法使用。需要以高速传输大量数据的设备通常使用直接内存访问(DMA)。DMA 设备硬件直接将传入的数据写入 RAM,并从 RAM 读取传出的数据。现代磁盘和网络设备使用 DMA。
DMA 设备的驱动程序将在 RAM 中准备数据,然后使用对控制寄存器的单个写入来告诉设备处理准备好的数据。当设备需要在不可预测的时间且不经常关注时,中断是有意义的。但是中断具有较高的 CPU 开销。因此,高速设备(如网络和磁盘控制器)使用减少中断需求的技巧。一种技巧是为整个传入或传出请求批次引发单个中断。另一种技巧是驱动程序完全禁用中断,并定期检查设备是否需要关注。这种技术称为轮询。如果设备执行操作非常快,则轮询是有意义的,但如果设备大部分时间处于空闲状态,则会浪费 CPU 时间。一些驱动程序根据当前设备负载动态地在轮询和中断之间切换。
UART 驱动程序。这在低数据传输速率下是有意义的,但对于生成或消耗数据非常快的设备,这种双重复制可能会显著降低性能。一些操作系统能够直接在用户空间缓冲区和设备硬件之间移动数据,通常使用 DMA。
背景:
使用一种称为 E1000 的网络设备来处理网络通信。对于 xv6(以及实验将要编写的驱动程序),E1000 看起来像是连接到真实以太网局域网(LAN)的真实硬件。实际上,驱动程序将与之通信的 E1000 是由 qemu 提供的仿真,连接到也由 qemu 仿真的 LAN。在这个仿真的 LAN 上,xv6(“客户机”)的 IP 地址为 10.0.2.15。Qemu 还安排运行 qemu 的计算机以 IP 地址 10.0.2.2 出现在 LAN 上。当 xv6 使用 E1000 将数据包发送到 10.0.2.2 时,qemu 将数据包传递到运行 qemu 的(真实)计算机上的相应应用程序(“主机”)。在本实验中将使用 QEMU 的“用户模式网络栈”。
Makefile 配置 QEMU 将所有传入和传出的数据包记录到实验室目录中的文件 packets.pcap 中。查看这些记录以确认 xv6 正在传输和接收您期望的数据包可能会有所帮助。要显示记录的数据包:
1 | |
实验题目本身已经向 xv6 中添加了一些文件。文件 kernel/e1000.c 包含 E1000 的初始化代码以及用于发送和接收数据包的空函数,实验任务就是填充这些函数。kernel/e1000_dev.h 包含 E1000 定义的寄存器和标志位的定义,这些定义在 Intel E1000 软件开发人员手册中有描述。kernel/net.c 和 kernel/net.h 包含一个简单的网络栈,实现了 IP、UDP 和 ARP 协议。这些文件还包含一个用于灵活数据结构来保存数据包的代码,称为 mbuf。最后,kernel/pci.c 包含当 xv6 启动时在 PCI 总线上搜索 E1000 的代码。
1. Your Job ()
完成 kernel/e1000.c 中的 e1000_transmit() 和 e1000_recv() 函数,以使驱动程序能够发送和接收数据包。
参考资料:
E1000 开发者指南(Section 2,3.2,3.3,4.1,13,14)
网络编程基础介绍及socket API的使用详解-CSDN博客
本手册涵盖了几种密切相关的以太网控制器。QEMU 模拟 82540EM。现在浏览第 2 章,了解一下该设备。要编写你的驱动程序,你需要熟悉第 3 章和第 14 章,以及 4.1(但不包括 4.1 的子部分)。你还需要将第 13 章作为参考。其他章节主要涵盖了你的驱动程序不需要与之交互的 E1000 的组件。一开始不用担心细节;只需了解一下文档的结构,以便以后能够找到所需内容。E1000 具有许多高级功能,其中大部分你可以忽略。完成这个实验只需要一小部分基本功能。
以下内容主要来自于MIT 公开课 MIT6.S081中的NetWorking,允许在同一个局域网上两台主机相互通讯的协议是以太网协议,当一个主机向另一个主机发送一个以太网帧(数据包),这是一串字节,为了让主机能够寻址到是哪个主机传来的数据包并正确的处理它们,需要一个报头(Header),本实验在 kernel/net.h 中定义了以太网数据包的相关结构体:
1 | |
接下来需要了解ARP(Address Resolution Protocol,地址解析协议),在互联网上通信,需要32位的IP(互联网地址),互联网中每个网络都有一个不同的编号即IP,路由器通过查看互联网地址来确定将数据包转发到哪个路由器或者互联网。当数据包从互联网到达以太网时,我们需要将32位的IP转换为48位的MAC(以太网地址),这时就要用使用ARP来解析地址。
1 | |
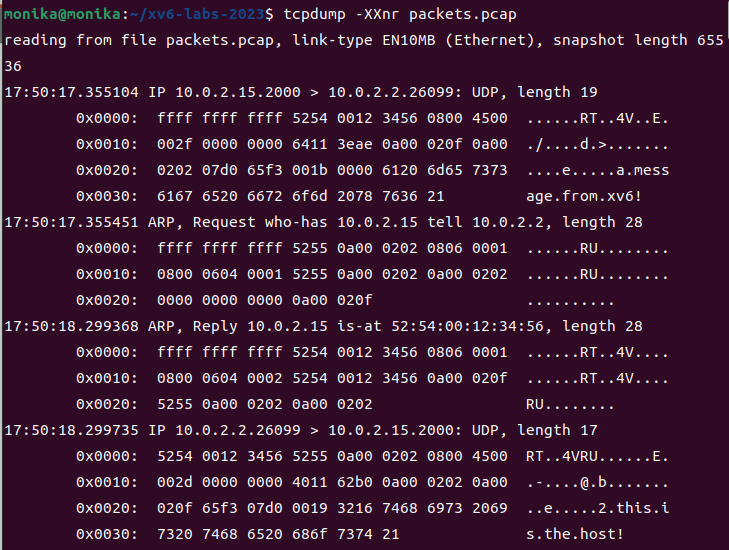
如何阅读tcpdump对于 ARP数据包的输出?以下面代码块的为例:
1 | |
第一行包括数据包到达的时间及基本信息。如第一个是请求第二个是响应。
后面三行为接收到的数据包的十六进制,每个数据包的前48位(对应16进制的前12位,也可以说是6个字节)对应的是广播地址,比如上方例子中全是f,这代表广播到本地网络上的所有主机的地址。接下来的48位是发送主机的以太网地址,按理来说它的高位(前24位)应该是网卡的制造商地址,但在本实验中由 qemu 模拟网卡并生成此地址。再接下来的16位(对应的是0806)是数据包的以太网类型,即type字段,对应上面代码块中的 ETHTYPE_ARP。在本例中最后的32位存放了目标ip地址(对应0a00020f)。右侧的部分是左侧部分的ASCII码对应的字节,当发送包含ASCII文本的数据包时这部分内容可能会有所帮助。
IP协议可以将数据包传送到互联网的任何位置,当数据包被发送到远程网络,离开本地的以太网后,以太网报头会不断更新,更新为下一跳的网络设备的地址,但IP地址等将保持不变,到达目标设备后,ip_p字段会告诉目的地主机要如何处理数据包。
1 | |
如何阅读tcpdump对于 IP 数据包的输出?以下面代码块的为例:
1 | |
第一行包括数据包到达的时间及基本信息。
后面三行的前48位对应的以太网目标地址。接下来的48位是发送主机的以太网地址,再接下来的16位(对应的是0800)是数据包的以太网类型,即type字段,对应上面代码块中的 ETHTYPE_IP。IP报头包括20个字节,即在十六进制下占用40位,故第一行的最后四位,整个第二行,第三行的前四位均为IP报头。报头的最后十六位,前八位代表源IP地址(0a00 020f),后八位代表目的IP地址(0a00 0202)。再往前对应四位的校验码(对应二进制16位,3eae)用于检验数据包是否损坏。再往前的两位为协议号(对应11,十进制对应17,在上方代码块中的 IPPROTO_UDP,说明这是一个UDP数据包)。
现在我们把数据包从一个主机传通过网络传送到了另一个主机上,但在这个主机上存在诸多应用程序,都需要从网络中接收数据包,如何区分数据包属于哪一个应用?如TCP,UDP等协议可以用于区分。TCP不仅将数据包传递到正确的应用程序,同时检测数据包是否丢失并重新发送它们,确保数据按顺序且不间断的传送。而UDP较为简单,只是将数据包传送到特定的应用程序。
1 | |
当具体的应用程序想要发送或接收数据包时,往往使用套接字API(Socket API),Unix 喜欢把设备抽象成文件,这里可以简单理解成把网卡也抽象成了一个文件描述符,某个应用可能要接收目的端口为 x 的数据包,它就调用套接字API并返回一个文件描述符,当有符合要求的数据包到达时就会到达该文件描述符上。
如何阅读tcpdump对于 UDP 数据包的输出?以下面代码块的为例:
1 | |
前面都一样,从第三行第五位开始共占十六位,分别对应上面四个字段。最后包含以ASCII码形式发送的信息。
网卡收到数据包后会生成中断,中断会触发中断例程,中断例程将数据包加到队列并返回。因为网卡通常只有一小部分内存用于存储数据包,而RAM中可以存储大量数据包,所以我们希望快速把数据包从网卡中取出并放入软件队列中。之后 IP 处理线程(也有可能是实体)将读取这些传入队列的数据包,如通过 UDP 将他们向上发送到套接字层并继续排队等待某个应用程序。另一种可能是这个主机是一台路由器,数据包从某个网卡进入,然后从一个或多个网卡再路由出去,这个过程仍然会读取传入队列并产生中断。
下面是一种落后的设计,网卡接收到数据包后存入网卡自己的队列中并立刻产生中断,中断后在主机的驱动程序中有一个循环,该循环会将这些数据包逐个字节复制到主机的内存中,这样做的效率较低。
所以在本实验中采取一种更新的方式,即网卡内部的缓冲区很小,网卡直接将数据包复制到主机的内存中等待驱动将它们取走。网卡依靠DMA环(指向数据包缓冲区的指针数组)来确定数据包应该存放的位置,所以当网卡驱动程序初始化时会在内存中分配一个数据包缓冲区并创建一个指向这些内存区域的指针数组。当数据包到达网卡时,将获取指针位置并在下一个空位复制数据包。
在 e1000.c 中提供的 e1000_init()函数将 E1000 配置为从 RAM 读取要传输的数据包,并将接收到的数据包写入 RAM。这种技术称为 DMA,即直接内存访问,指的是 E1000 硬件直接将数据包写入/读取到/从 RAM 中。
由于数据包的突发可能比驱动程序处理它们的速度更快,e1000_init()为 E1000 提供了多个缓冲区,E1000 可以将数据包写入这些缓冲区。E1000 需要这些缓冲区由 RAM 中的“描述符”数组来描述;每个描述符包含一个 RAM 地址,E1000 可以在该地址写入接收到的数据包。struct rx_desc 描述了描述符的格式。描述符数组称为接收环或接收队列。从某种意义上说,它是一个循环环,当卡或驱动程序到达数组的末尾时,它会回绕到开头。e1000_init()使用 mbufalloc()为 E1000 分配用于 DMA 的 mbuf 数据包缓冲区。还有一个发送环,驱动程序应该将其希望 E1000 发送的数据包放置在其中。e1000_init()将两个环配置为具有 RX_RING_SIZE 和 TX_RING_SIZE 的大小。
当 net.c 中的网络栈需要发送数据包时,它会使用包含要发送的数据包的 mbuf 调用 e1000_transmit()。你的发送代码必须将数据包数据的指针放置在 TX(发送)环中的描述符中。struct tx_desc 描述了描述符的格式。你需要确保每个 mbuf 最终都被释放,但只有在 E1000 完成传输数据包后(E1000 在描述符中设置 E1000_TXD_STAT_DD 位来表示这一点)。
1 | |
当 E1000 从以太网接收每个数据包时,它会将数据包 DMA 到下一个 RX(接收)环描述符中 addr 指向的内存。如果 E1000 中断尚未挂起,E1000 会要求 PLIC 在中断启用后尽快传递一个中断。你的 e1000_recv()代码必须扫描 RX 环,并通过调用 net_rx()将每个新数据包的 mbuf 传递给网络栈(在 net.c 中)。然后,你需要分配一个新的 mbuf 并将其放入描述符中,以便当 E1000 再次到达 RX 环中的该点时,它会找到一个新的缓冲区来 DMA 一个新的数据包。
1 | |
tcpdump -XXnr packets.pcap 输出:
make grade 输出:
八、Lab8: Locking
本章重点介绍一种广泛使用的技术:锁。锁提供互斥,确保一次只有一个 CPU 可以持有锁。如果程序员将每个共享数据项与一个锁相关联,并且代码在使用该数据项时始终持有相关联的锁,那么该数据项将一次仅由一个 CPU 使用。在这种情况下,我们说锁保护了数据项。尽管锁是一种易于理解的并发控制机制,但锁的缺点是它们可能会限制性能,因为它们会序列化并发操作。
完成实验之前,首先阅读xv6文档的Chapter 6: Locking,Section 3.5,Section 8.1 至 8.3: Overview, Buffer cache layer等部分及相关代码,以下是这部分的主要内容:
1.概述
在之前的实验中已经对锁有过初步了解,例子在这里不在赘述。在获取和释放锁之间的指令序列通常被称为临界区。 锁通常被称为保护列表。 当我们说锁保护数据时,我们实际上是说锁保护了一些适用于数据的不变量集合。不变量是跨操作维护的数据结构的属性。通常,操作的正确行为取决于操作开始时不变量是否为真。操作可能会暂时违反不变量,但必须在完成之前重新建立它们。正确使用锁确保一次只有一个 CPU 可以在临界区中操作数据结构,因此没有 CPU 会在数据结构的不变量不成立时执行数据结构操作。
可以将锁视为序列化并发临界区,以便它们一次运行一个,从而保持不变量(假设临界区单独是正确的),也可以将由同一锁保护的临界区视为相互原子的,这样每个临界区只看到早期临界区的完整更改集,而永远不会看到部分完成的更新。
尽管对正确性很有用,但锁本质上限制了性能。如果多个进程同时想要同一个锁,或者锁经历争用,我们说这些进程冲突。内核设计中的一个主要挑战是避免锁争用以追求并行性。Xv6 在这方面做得很少,但复杂的内核专门组织数据结构和算法以避免锁争用。
2.Code: Locks
Xv6 有两种类型的锁:自旋锁和睡眠锁。Xv6 将自旋锁表示为 struct spinlock(kernel/spinlock.h:2)。结构中的重要字段是 locked,当锁可用时为 0,持有锁时为非 0。从逻辑上讲,Xv6 应该通过执行类似于以下的代码来获取锁:
1 | |
不幸的是,这种实现并不能保证在多处理器上的互斥性。可能会发生两个 CPU 同时到达高亮处,看到 lk->locked 为 0,然后都获取锁。在这一点上,两个不同的 CPU 持有锁,这违反了互斥性属性。我们需要一种方法来使这一部分作为一个原子(即不可分割)的步骤执行。
由于锁被广泛使用,多核处理器通常提供指令来实现这部分代码的原子版本。在 RISC-V 上,这个指令是 amoswap r, a。amoswap 读取内存地址 a 的值,将寄存器 r 的内容写入该地址,并将读取的值放入 r。也就是说,它交换了寄存器和内存地址的内容。它使用特殊硬件以原子方式执行此序列,以防止任何其他 CPU 在读取和写入之间使用该内存地址。
Xv6 的 acquire 使用可移植的 C 库调用 __sync_lock_test_and_set,该调用归结为 amoswap 指令;返回值是 lk->locked 的旧(交换)内容。acquire 函数将交换包装在一个循环中,重试(自旋)直到它获取了锁。每次迭代将一个交换到 lk->locked 中,并检查前一个值;如果前一个值为零,那么我们已经获取了锁,并且交换将 lk->locked 设置为 1。如果前一个值为 1,那么其他 CPU 持有锁,并且我们原子地将一个交换到 lk->locked 中并没有改变其值。
1 | |
一旦获取了锁,acquire 就会记录获取锁的 CPU,用于调试。lk->cpu 字段受到锁的保护,并且只能在持有锁时进行更改。函数 release(kernel/spinlock.c:47)与 acquire 相反:它清除 lk->cpu 字段,然后释放锁。从概念上讲,释放只需要将 lk->locked 赋值为零。C 标准允许编译器使用多个存储指令来实现赋值,因此 C 赋值可能对于并发代码是非原子的。相反,release 使用 C 库函数 __sync_lock_release,该函数执行原子赋值。这个函数也归结为 RISC-V amoswap 指令。
3.Code: Using locks
Xv6 在许多地方使用锁来避免竞态条件,使用锁的一个困难部分是决定使用多少个锁以及每个锁应该保护哪些数据和不变量。有几个基本原则。首先,任何时候一个变量可以被一个 CPU 写入,而另一个 CPU 可以同时读取或写入它,应该使用锁来防止这两个操作重叠。其次,请记住,锁保护不变量:如果一个不变量涉及多个内存位置,通常所有这些位置都需要由一个锁来保护,以确保不变量得到维护。
上述规则说明了何时需要锁,但没有说明何时不需要锁,为了提高效率,重要的是不要过度锁定,因为锁会减少并行性。如果并行性不重要,那么可以安排只有一个线程,而不必担心锁。一个简单的内核可以在多核处理器上通过在进入内核时获取一个锁并在退出内核时释放该锁来实现这一点(尽管阻塞系统调用,如管道读取或等待会带来问题)。许多单核操作系统已经通过这种方法转换为在多核处理器上运行,有时称为“大内核锁”,但这种方法牺牲了并行性:一次只能在内核中执行一个 CPU。如果内核进行任何繁重的计算,使用更大的更细粒度的锁集将更有效,这样内核可以同时在多个 CPU 上执行。
作为粗粒度锁定的一个例子,xv6 的 kalloc.c 分配器有一个由单个锁保护的单个空闲列表。如果不同 CPU 上的多个进程同时尝试分配页面,每个进程都必须在 acquire 中旋转等待轮到自己。旋转会浪费 CPU 时间,因为它不是有用的工作。如果对锁的争用浪费了大量的 CPU 时间,也许可以通过改变分配器设计来提高性能,使其具有多个空闲列表,每个列表都有自己的锁,以允许真正的并行分配。
作为细粒度锁定的一个例子,xv6 为每个文件都有一个单独的锁,因此操作不同文件的进程通常可以在不等待彼此的锁的情况下进行。如果希望允许进程同时写入同一文件的不同区域,则可以使文件锁定方案更加细粒度。最终,锁粒度决策需要由性能测量以及复杂性考虑因素驱动。 随着后续章节解释 xv6 的每个部分,它们将提到 xv6 使用锁来处理并发的例子。下图列出了 xv6 中的所有锁。

4.Deadlock and lock ordering
如果通过内核的代码路径必须同时持有多个锁,那么所有代码路径以相同的顺序获取这些锁就非常重要。如果它们不这样做,就存在死锁的风险。假设 xv6 中的两个代码路径需要锁 A 和 B,但代码路径 1 以 A 然后 B 的顺序获取锁,而另一个路径以 B 然后 A 的顺序获取锁。假设线程 T1 执行代码路径 1 并获取锁 A,线程 T2 执行代码路径 2 并获取锁 B。接下来,T1 将尝试获取锁 B,T2 将尝试获取锁 A。由于两种情况下另一个线程都持有所需的锁,并且在其获取返回之前不会释放它,因此这两个获取将无限期阻塞。为了避免这种死锁,所有代码路径必须以相同的顺序获取锁。需要全局锁获取顺序意味着锁实际上是每个函数规范的一部分:调用者必须以导致锁以商定的顺序获取的方式调用函数。
那么当存在需要同时获取多个锁的情况怎么办?简而言之就是要严格按照顺序来:Xv6 有许多涉及进程锁(struct proc 中的锁)的长度为 2 的锁顺序链(例子在Lab6中有提到过)。例如,consoleintr(kernel/console.c:136)是处理输入字符的中断例程。当换行符到达时,任何等待控制台输入的进程都应该被唤醒。为此,consoleintr 在调用 wakeup 时持有 cons.lock,wakeup 会获取等待进程的锁以将其唤醒。因此,避免全局死锁的锁顺序包括 cons.lock 必须在任何进程锁之前获取的规则。文件系统代码包含 xv6 最长的锁链。例如,创建文件需要同时持有目录锁、新文件的 inode 锁、磁盘块缓冲区锁、磁盘驱动程序的 vdisk_lock 和调用进程的 p->lock。为了避免死锁,文件系统代码总是按照前面句子中提到的顺序获取锁。
遵守全局避免死锁的顺序可能非常困难。有时锁顺序与逻辑程序结构冲突,例如,也许代码模块 M1 调用模块 M2,但锁顺序要求在 M1 中的锁之前获取 M2 中的锁。有时锁的身份事先不知道,也许是因为必须持有一个锁才能发现下一个要获取的锁的身份。这种情况在文件系统中查找路径名中的连续组件时以及在 wait 和 exit 代码中搜索进程表以查找子进程时都会出现。最后,死锁的危险通常是对锁定方案可以细化到何种程度的限制,因为更多的锁通常意味着更多的死锁机会。避免死锁的需要通常是内核实现的一个主要因素。
5.Re-entrant locks(可重入锁)
可以通过使用可重入锁(也称为递归锁)来避免一些死锁和锁排序,可重入锁就是可以多次 acquire 的锁,只要该进程拥有锁,再次调用 acquire 就不会像xv6那样出发panic。 然而,可重入锁使得对并发的推理更加困难:可重入锁打破了锁导致关键部分相对于其他关键部分是原子的直觉。考虑以下两个函数 f 和 g:
1 | |
查看这段代码片段,直觉是 call_once 只会被调用一次:要么被 f 调用,要么被 g 调用,但不会被两者都调用。 但是,如果允许可重入锁,并且 h 碰巧调用了 g,那么 call_once 将被调用两次。
如果不允许可重入锁,那么 h 调用 g 会导致死锁,这也不是很好。但是,假设调用 call_once 是一个严重的错误,那么死锁是更可取的。内核开发人员会观察到死锁(内核恐慌),并可以修复代码以避免它,而调用 call_once 两次可能会默默地导致难以追踪的错误。
出于这个原因,xv6 使用更易于理解的不可重入锁。只要程序员牢记锁定规则,然而,任何一种方法都可以使其工作。如果 xv6 要使用可重入锁,就必须修改 acquire 以注意到锁当前由调用线程持有。还必须以类似于接下来讨论的 push_off 的方式,向 struct spinlock 添加嵌套获取的计数。
6.Locks and interrupt handlers
一些 xv6 自旋锁保护的是线程和中断处理程序都使用的数据。例如,时钟中断处理程序可能会在大约同一时间增加 ticks(内核/trap.c:164),而内核线程在 sys_sleep(内核/sysproc.c:59)中读取 ticks。锁 tickslock 对这两个访问进行了串行化。
自旋锁和中断的交互带来了潜在的危险。假设 sys_sleep 持有 tickslock,并且其 CPU 被一个定时器中断。clockintr 将尝试获取 tickslock,发现它被持有,并等待它被释放。在这种情况下,tickslock 将永远不会被释放:只有 sys_sleep 可以释放它,但是 sys_sleep 将不会继续运行,直到 clockintr 返回。因此,CPU 将死锁,任何需要该锁的代码也将冻结。
为了避免这种情况,如果一个中断处理程序使用了一个自旋锁,那么 CPU 绝不能在启用中断的情况下持有该锁。xv6 更为保守:当 CPU 获取任何锁时,xv6 总是禁用该 CPU 上的中断。中断仍然可能发生在其他 CPU 上,因此中断的 acquire 可以等待线程释放自旋锁;只是不能在同一个 CPU 上。
Xv6 在 CPU 不持有自旋锁时重新启用中断;它必须进行一些簿记工作来处理嵌套的临界区。acquire 调用 push_off,release 调用 pop_off 来跟踪当前 CPU 上的锁嵌套级别。当计数达到零时,pop_off 恢复在最外层临界区开始时存在的中断启用状态。intr_off 和 intr_on 函数分别执行 RISC-V 指令来禁用和启用中断。
1 | |
重要的是,acquire 在设置锁之前严格调用 push_off。如果两者颠倒,那么在启用中断的情况下持有锁时会有一个短暂的窗口,一个定时中断会使系统死锁。同样,release 在释放锁之后才调用 pop_off。
7.Instruction and memory ordering
一般我们认为程序是按照源代码语句出现的顺序执行的。对于单线程代码来说,这是一个合理的心理模型,但当多个线程通过共享内存交互时,这是不正确的。一个原因是编译器以不同于源代码所暗示的顺序发出加载和存储指令,并且可能完全省略它们(例如,通过在寄存器中缓存数据)。另一个原因是 CPU 可能会乱序执行指令以提高性能。这样的例子在之前 Lab4 中已经有所提及。CPU 可能会注意到在指令序列 A 和 B 之间不存在依赖关系。CPU 可能会首先启动指令 B,要么是因为它的输入在 A 的输入之前准备好,要么是为了重叠执行 A 和 B,例子在此省略。
为了告诉硬件和编译器不要重新排序,xv6 在 acquire(kernel/spinlock.c:22)和 release(kernel/spinlock.c:47)中都使用了 _sync_synchronize()。这是一个内存屏障:它告诉编译器和 CPU 不要跨屏障重新排序加载或存储,防止出现错误。
8.Sleep locks
由于实验部分和官方文档并非同顺序,这部分内容在多线程 Lab6 对应的文档部分已经有所涉及,简而言之就是如果一个线程持有自旋锁,但它消耗时间较长(如文件系统在磁盘上读写文件内容时会保持文件锁定,而这些磁盘操作可能需要数十毫秒),这样别的线程想要获取CPU就需要等待很久,但这个线程又不能在获取锁的情况下中断并让出CPU,为了解决这样的情况,xv6 提供了睡眠锁,acquiresleep(kernel/sleeplock.c:22)在等待时让出 CPU。在较高层次上,睡眠锁有一个由自旋锁保护的锁定字段,acquiresleep 对 sleep 的调用原子地让出 CPU 并释放自旋锁。结果是,其他线程可以在 acquiresleep 等待时执行。
由于睡眠锁允许中断,因此它们不能用于中断处理程序。由于 acquiresleep 可能会让出 CPU,因此睡眠锁不能用于自旋锁临界区内部(尽管自旋锁可以用于睡眠锁临界区内部)。自旋锁最适合短的临界区,因为等待它们会浪费 CPU 时间;睡眠锁适用于长时间的操作。
9.实际情况
使用锁进行编程仍然很复杂,最好将锁隐藏在更高层次的结构中,例如同步队列,尽管 xv6 没有这样做。如果使用锁进行编程,更好的做法是使用一种工具来尝试识别竞争条件,因为很容易错过需要锁的不变量。
大多数操作系统支持 POSIX 线程(Pthreads),它允许用户进程在不同的 CPU 上同时运行多个线程。Pthreads 支持用户级锁、屏障等。Pthreads 还允许程序员可选地指定锁应该是可重入的。
在用户级支持 Pthreads 需要操作系统的支持。例如,如果一个 pthread 在系统调用中阻塞,同一进程的另一个 pthread 应该能够在该 CPU 上运行。作为另一个例子,如果一个 pthread 更改其进程的地址空间(例如,映射或取消映射内存),内核必须安排其他运行同一进程线程的 CPU 更新其硬件页表以反映地址空间的更改。
可以在没有原子指令的情况下实现锁,但这很昂贵,并且大多数操作系统都使用原子指令。 如果许多 CPU 同时尝试获取同一锁,则锁可能很昂贵。如果一个 CPU 在其本地缓存中缓存了一个锁,而另一个 CPU 必须获取该锁,则更新包含该锁的缓存行的原子指令必须将该行从一个 CPU 的缓存移动到另一个 CPU 的缓存,并且可能使缓存行的任何其他副本无效。从另一个 CPU 的缓存中获取缓存行可能比从本地缓存中获取缓存行昂贵几个数量级。
为了避免与锁相关的开销,许多操作系统使用无锁数据结构和算法。例如,可以实现一个像本章开头那样的链表,在链表搜索期间不需要锁,并且只需一个原子指令即可将一个项目插入链表。然而,无锁编程比编程锁更复杂;例如,必须担心指令和内存重新排序。使用锁进行编程已经很困难,因此 xv6 避免了无锁编程的额外复杂性。
1.Memory allocator ()
多核机器上并行性差的常见症状是高锁竞争。提高并行性通常涉及更改数据结构和锁定策略,以减少争用。你将为 xv6 内存分配器和块缓存执行此操作。
程序user/kalloctest对xv6的内存分配器进行压力测试:三个进程扩大和缩小其地址空间,导致许多对kalloc和kfree的调用。kalloc和kfree获取kmem.lock。
怎么理解 kalloctest 的输出内容,如下所示,它会输出由于试图获取另一个核心已经持有的锁而导致的acquire循环迭代次数,在acquire中的循环迭代次数是锁竞争的一个粗略度量。
1 | |
kalloctest 中锁竞争的根本原因是 kalloc() 有一个单一的空闲列表,由一个单一的锁保护。为了消除锁竞争,将不得不重新设计内存分配器,以避免单个锁和列表。基本思想是为每个 CPU 维护一个空闲列表,每个列表都有自己的锁。不同 CPU 上的分配和释放可以并行运行,因为每个 CPU 将在不同的列表上操作。具体的工作内容就是更改kmem结构体从单个变为数组,让每个CPU都具有单独的kmem结构体,分开锁以及freelist等具体项,同时更改kernel/kalloc.c中的相关方法,这样就能降低锁竞争的次数。
使用 kernel/param.h 中的常量 NCPU 来确认 CPU的数量。对原先的kmem结构体进行修改,改为kmem结构体数组,数组的大小为 NCPU即可。这样相当于有了 NCPU 个kmem,我们需要仿照原先的 kinit 按部就班的对每个kmem结构体进行初始化。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17// kernel/kalloc.c
struct {
struct spinlock lock;
struct run *freelist;
} kmem[NCPU];
void
kinit()
{
for (int i = 0; i < NCPU; i++)
{
// 这里我们参考实验提示给所有的锁都命名为kmem
initlock(&kmem[i].lock, "kmem");
}
freerange(end, (void*)PHYSTOP);
}让 freerange 将所有空闲内存分配给运行 freerange 的 CPU。 这个操作具体实现由kfree函数实现,这里我们需要对 kfree进行修改。实验提示说明函数 cpuid 返回当前核心编号,但只有在中断关闭时调用它并使用其结果才是安全的,使用 push_off() 和 pop_off() 来关闭和打开中断。 获取 cpuid 并对该cpu对应的 kmem 结构体的锁和 freelist 进行修改实现上述操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29void
freerange(void *pa_start, void *pa_end)
{
char *p;
p = (char*)PGROUNDUP((uint64)pa_start);
for(; p + PGSIZE <= (char*)pa_end; p += PGSIZE)
kfree(p);
}
void
kfree(void *pa)
{
// 这一部分不需要修改,我们仍然需要把pa指向的页面进行覆盖
struct run *r;
if(((uint64)pa % PGSIZE) != 0 || (char*)pa < end || (uint64)pa >= PHYSTOP)
panic("kfree");
memset(pa, 1, PGSIZE);
r = (struct run*)pa;
// 根据提示在中断后获取 cpuid
push_off();
int cid = cpuid();
pop_off();
// 对cpuid对应的kmem结构体进行修改
acquire(&kmem[cid].lock);
r->next = kmem[cid].freelist;
kmem[cid].freelist = r;
release(&kmem[cid].lock);
}原先的kalloc函数也是针对一个 kmem 结构体实现的,难点题目已经提及,当一个 CPU 的空闲列表为空,但另一个 CPU 的列表有空闲内存的情况;在这种情况下,一个 CPU 必须“窃取”另一个 CPU 的空闲列表的一部分。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42void *
kalloc(void)
{
struct run *r;
struct run *new_r;
// 同样获取cpuid
push_off();
int cid = cpuid();
pop_off();
acquire(&kmem[cid].lock);
r = kmem[cid].freelist;
// 如果freelist尚有空余则和未修改的kalloc相同
// 直接从freelist中取一个空页面即可
if(r){
kmem[cid].freelist = r->next;
}
// 如果freelist已经没有空闲的页面就要从别的cpu的freelist中借取页面
else{
// 直接遍历剩下cpu的freelist,哪个有空的就借走
for (int i = 0; i < NCPU; i++)
{
if (i == cid){
continue;
}
acquire(&kmem[i].lock);
new_r = kmem[i].freelist;
if (new_r)
{
// 从别的cpu的空闲页面列表中借取页面
r = new_r;
kmem[i].freelist = new_r->next;
release(&kmem[i].lock);
break;
}
release(&kmem[i].lock);
}
}
release(&kmem[cid].lock);
if(r)
memset((char*)r, 5, PGSIZE); // fill with junk
return (void*)r;
}
2.Buffer cache ()
先跳过该实验阅读第八章文件系统的相关内容,这部分内容在下个实验中介绍。
如果多个进程密集地使用文件系统,它们很可能会争夺 bcache.lock,该锁保护 kernel/bio.c 中的磁盘块缓存。
查看 kernel/bio.c 中的代码,会看到 bcache.lock 保护缓存块缓冲区的列表、每个块缓冲区中的引用计数(b->refcnt)以及缓存块的标识(b->dev 和 b->blockno)。 修改块缓存,使得在运行 bcachetest 时,bcache 中所有锁的 acquire 循环迭代次数接近零。
修改 bget 和 brelse,使得对 bcache 中不同块的并发查找和释放不太可能在锁上冲突(例如,不必都等待 bcache.lock)。必须保持每个块最多只有一个副本被缓存的不变性。你不能增加缓冲区的数量;必须正好有 NBUF(30)个缓冲区。你修改后的缓存不需要使用 LRU 替换,但当它在缓存中未命中时,必须能够使用任何 refcnt 为零的 NBUF 结构 bufs。
题目提示使用每个哈希桶都有一个锁的哈希表来查找缓存中的块号。 参考第九章的第二部分Buffer cache layer,可以看到未经修改的xv6使用一个链表来查询缓存中的块,找不到再把从最近访问最少的给覆盖了。如何使用哈希表优化?用哈希链表取代原先的双向链表,然后为每个桶上锁,只有比如文件系统对同一个哈希桶进行请求时才需要等待。
首先将对原先的结构体进行修改,提示让我们使用固定数量且质数个桶(例如13),那不妨就使用13。删除所有缓冲区的链表(bcache.head 等),不要实现 LRU(Least Recently Used,一种缓存淘汰策略,最近用的最少的先淘汰)。同时编写getkey函数,用于获取哈希表的key。mapNames数组存放对应的桶的名称。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25#define MapNum 13
struct {
struct spinlock lock;
struct buf buf[NBUF];
// 这里原先是链表头,现在改成哈希表
struct buf hashMap[MapNum]; // 哈希表
struct spinlock mapLock[MapNum]; // 每个桶对应的锁
} bcache;
// 原先struct buf中的next指向链表头
// 现在指向哈希表头即可
// 获取key
int getKey(int blockno){
int key = blockno % MapNum;
return key;
}
char *mapNames[MapNum] = {
"bcache-1",
"bcache-2",
"bcache-3",
// 省略若干行
};修改对应的 binit,:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20void
binit(void)
{
struct buf *b;
int index;
// Create hashmap of buffers
for (i = 0; i < MapNum; i++){
initlock(&bcache.mapLock[i], mapNames[i]);
}
// 初始化缓冲区和每一个捅
for (b = bcache.buf; b < bcache.buf + NBUF; b++){
// 遍历缓冲区中的每一个buf,放入哈希链表中
index = (b - bcache.buf) % MapNum;
acquire(&bcache.mapLock[index]);
b->next = bcache.hashMap[index].next;
bcache.hashMap[index].next = b;
release(&bcache.mapLock[index]);
initsleeplock(&b->lock, "bcache");
}
}修改 bpin和 bunpin ,获取key后获取锁修改其引用计数。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15void
bpin(struct buf *b) {
int key = getKey(b->blockno);
acquire(&bcache.mapLock[key]);
b->refcnt++;
release(&bcache.mapLock[key]);
}
void
bunpin(struct buf *b) {
int key = getKey(b->blockno);
acquire(&bcache.mapLock[key]);
b->refcnt--;
release(&bcache.mapLock[key]);
}修改 bget ,可以选择任何 refcnt == 0 的块,而不是最近最少使用的块。可能无法原子地检查缓存的 buf 并(如果未缓存)找到未使用的 buf;如果缓冲区不在缓存中,需要释放所有锁并从头开始。在 bget 中序列化查找未使用的 buf 是可以的(即在缓存中查找未命中时选择要重用的缓冲区的部分)。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84// 获取指定设备和块号的缓冲区
static struct buf*
bget(uint dev, uint blockno)
{
struct buf *b, *cur = 0, *pre = 0;
int i, currentKey;
int key = getKey(blockno);
acquire(&bcache.mapLock[key]); // 获取哈希桶锁
// 在对应的桶中查找符合条件的缓冲区
// 找到则增加引用计数,释放锁并睡眠等待缓冲区
for (b = bcache.hashMap[key].next; b!= 0; b = b->next)
{
if (b->dev == dev && b->blockno == blockno)
{
b->refcnt++;
release(&bcache.mapLock[key]);
acquiresleep(&b->lock);
return b;
}
}
// 若未找到,则释放桶锁并获取全局锁
release(&bcache.mapLock[key]);
acquire(&bcache.lock);
// 遍历其他桶
for (i = 0; i < MapNum; i++)
{
currentKey = (key + i) % MapNum; // 计算当前桶号
acquire(&bcache.mapLock[currentKey]); // 获取当前桶锁
// 检查当前桶中是否已存在符合条件的缓冲区
if (currentKey == key)
{
for (b = bcache.hashMap[key].next; b!= 0; b = b->next)
{
if (b->dev == dev && b->blockno == blockno)
{
b->refcnt++;
release(&bcache.mapLock[currentKey]);
release(&bcache.lock);
acquiresleep(&b->lock);
return b;
}
}
}
// 查找当前桶中可重置的缓冲区
for (b = &bcache.hashMap[currentKey]; b->next!= 0; b = b->next)
{
if (b->next->refcnt == 0)
{
pre = b; // 记录前一个缓冲区指针
cur = b->next; // 记录可复用的缓冲区指针
}
}
// 若找到可复用的缓冲区
if (cur)
{
// 更新缓冲区信息
cur->dev = dev;
cur->blockno = blockno;
cur->valid = 0;
cur->refcnt = 1;
// 将缓冲区从原哈希桶的链表中移除
pre->next = cur->next;
release(&bcache.mapLock[currentKey]);
// 将缓冲区添加到新哈希桶的链表中
acquire(&bcache.mapLock[key]);
cur->next = bcache.hashMap[key].next;
bcache.hashMap[key].next = cur;
release(&bcache.mapLock[key]);
release(&bcache.lock);
acquiresleep(&cur->lock);
return cur;
}
// 释放当前桶锁
release(&bcache.mapLock[currentKey]);
}
// 不应运行到此处,必须加panic,否则报错
panic("to end");
}修改 brelse ,不需要获取 bcache 锁。
1
2
3
4
5
6
7
8
9
10
11void
brelse(struct buf *b)
{
int key = getKey(b->blockno);
if(!holdingsleep(&b->lock))
panic("brelse");
releasesleep(&b->lock);
acquire(&bcache.mapLock[key]);
b->refcnt--;
release(&bcache.mapLock[key]);
}运行截屏
![image.png]()
九、Lab9: File system
文件系统的目的是组织和存储数据。文件系统通常支持用户和应用之间的数据共享,以及持久性,以便在重启后仍然可用。 xv6 文件系统提供了类似 Unix 的文件、目录和路径名,并将其数据存储在 virtio 磁盘上以实现持久性。文件系统需要磁盘上的数据结构来表示命名的目录和文件的树形结构,记录每个文件内容所占据的块的身份,并记录磁盘上的哪些区域是空闲的。 其支持崩溃恢复,如果发生崩溃(例如电源故障),文件系统必须在重新启动后仍然正常工作。
开始实验前阅读官方文档第八章有关文件系统的部分,以下是这部分的主要内容:
1.概述
xv6 文件系统实现分为七个层次,如下图所示。从下到上,磁盘层在虚拟硬盘上读取和写入块。缓存层缓存磁盘块并同步对它们的访问,确保在任何时候只有一个内核进程可以修改存储在任何特定块中的数据。日志层允许上层将多个块的更新包装在一个事务中,并确保在崩溃时(即全部更新或无更新)这些块原子地更新。

inode 层为每个文件提供单独的文件,每个文件都由一个唯一的 inode 编号和一些保存文件数据的块表示。目录层将每个目录实现为一种特殊的 inode,其内容是一个目录条目序列,每个条目包含一个文件名和 inode 编号。路径名层提供类似 /usr/rtm/xv6/fs.c 这样的分层路径名,并使用递归查找解析它们。文件描述符层通过文件系统接口抽象许多 Unix 资源(例如管道、设备、文件等),简化了应用程序开发人员的工作。
磁盘硬件将数据分为编号的 512 字节块(也称为扇区),即扇区 0 是第一个 512 字节,扇区 1 是下一个。操作系统用于其文件系统的块大小可能与磁盘使用的扇区大小不同,但通常块大小是扇区大小的倍数。Xv6 将其读取到内存中的块副本存储在类型为 struct buf 的对象中(kernel/buf.h:1)。存储在此结构中的数据有时与磁盘不同步:它可能尚未从磁盘中读取(磁盘正在处理它,但尚未返回扇区的内容),或者它可能已经被软件更新,但尚未写入磁盘。
1 | |
文件系统必须有一个计划来指示它在磁盘上存储 inode 和内容块的位置。为此,xv6 将磁盘划分为几个部分,如下图所示。文件系统不使用块 0(它保存引导扇区)。块 1 被称为超级块;它包含有关文件系统的元数据(文件系统大小(以块为单位)、数据块数量、inode 数量以及日志中的块数)。从 2块开始到32块结束的块是日志。日志之后是 inode,从32块开始到45块结束,每个块有多个 inode。在这些之后是位图(bitmap)块,跟踪哪些数据块正在使用,位图块只占用一块。剩余的块是数据块;每个数据块要么在位图块中标记为空闲,要么保存文件或目录的内容。超级块由一个名为 mkfs 的单独程序填充,该程序构建初始文件系统。日志块,inode块和bit map块也被称为元数据块,它们并不存储实际数据,但为文件系统保存元数据信息来完成工作。

2.Buffer cache layer
缓冲区缓存有两个任务:
- 同步对磁盘块的访问,以确保内存中只有一个块的副本,并且一次只有一个内核线程使用该副本;
- 缓存常用块,以便它们不需要从慢速磁盘重新读取。
缓冲区缓存有固定数量的缓冲区来保存磁盘块,这意味着如果文件系统请求一个不在缓存中的块,缓冲区缓存必须回收当前持有其他块的缓冲区。缓冲区缓存为新块回收最近最少使用的缓冲区。假设最近最少使用的缓冲区是不太可能很快再次使用的缓冲区。以下是它的具体实现:
1 | |
上方代码块中的 bread 调用bget来获取 buf ,以下为bget的具体代码:
1 | |
每个磁盘扇区最多只能有一个缓存缓冲区,以确保读取器能够看到写入操作,并且因为文件系统使用缓冲区锁进行同步。bget 函数在 bcache.lock 临界区之外获取缓冲区的睡眠锁是安全的,因为非零的 b->refcnt 会阻止缓冲区被用于不同的磁盘块。睡眠锁保护对块缓冲内容的读取和写入,而 bcache.lock 保护有关哪些块被缓存的信息。 如果所有缓冲区都很忙,则意味着同时执行文件系统调用的进程过多;bget 函数会触发恐慌。
一旦 bread 函数读取了磁盘(如果需要)并将缓冲区返回给调用者,调用者就可以独占使用该缓冲区,并可以读取或写入数据字节。如果调用者确实修改了缓冲区,则必须在释放缓冲区之前调用 bwrite 函数将更改的数据写入磁盘。
3.Logging layer
崩溃恢复这个问题出现是因为许多文件系统操作涉及到对磁盘的多次写入,而在部分写入之后发生崩溃可能会使磁盘上的文件系统处于不一致的状态。例如,假设在文件截断(file truncation,将文件长度设置为零并释放其内容块)期间发生崩溃。根据磁盘写入的顺序,崩溃可能会留下一个带有对已标记为空闲的内容块的引用的索引节点,或者可能会留下一个已分配但未引用的内容块。
Xv6 通过一种简单的日志形式解决了文件系统操作期间崩溃的问题。Xv6 系统调用不会直接写入磁盘上的文件系统数据结构。相反,它将其希望进行的所有磁盘写入的描述放入磁盘上的日志中。一旦系统调用记录了其所有写入,它就会向磁盘写入一个特殊的提交记录,日志包含一个完整的操作。此时,系统调用将写入复制到磁盘上的文件系统数据结构中。在这些写入完成后,系统调用会擦除磁盘上的日 志。
如果系统崩溃并重新启动,文件系统代码将在运行任何进程之前从崩溃中恢复。如果日志被标记为包含完整的操作,则恢复代码将复制写入到它们在磁盘上的文件系统中的所属位置。如果日志未被标记为包含完整的操作,则恢复代码将忽略该日志。恢复代码通过擦除日志完成。
如果崩溃发生在操作提交之前,则磁盘上的日志将不会被标记为完整,恢复代码将忽略它,并且磁盘的状态将好像操作甚至没有开始。如果崩溃发生在操作提交之后,则恢复将重放操作的所有写入,可能会重复它们,如果操作已经开始将它们写入磁盘上的数据结构。在任何一种情况下,日志都使操作相对于崩溃是原子的。
为了允许不同进程并发执行文件系统操作,日志系统可以将多个系统调用的写入累积到一个事务中。因此,单个提交可能涉及多个完整系统调用的写入。为了避免将系统调用拆分为多个事务,日志系统仅在没有文件系统系统调用正在进行时才提交。Xv6 在磁盘上分配固定数量的空间来保存日志,事务中系统调用写入的总块数必须适合该空间。
将多个事务一起提交的想法称为组提交。组提交通过将提交的固定成本分摊到多个操作上来减少磁盘操作的数量。组提交还同时向磁盘系统提供更多并发写入,也许允许磁盘在一次磁盘旋转期间写入所有这些写入。Xv6 的 virtio 驱动程序不支持这种批处理,但 xv6 的文件系统设计允许这样做。
日志位于超级块中指定的已知固定位置。它由一个头块和一系列更新的块副本(“记录块”)组成。xv6 在事务提交时写入头块,并在将记录块复制到文件系统后将计数设置为零(下面的 n )。因此,在事务中途崩溃将导致日志头块中的计数为零;在提交后崩溃将导致非零计数。为了更好理解后面的内容,先对上述基本数据结构进行了解:
1 | |
接下来了解具体的代码实现,日志系统的调用可以简化成这样:
1 | |
begin_op( kernel/log.c :127 )会等待,直到日志系统当前没有正在提交,并且有足够的未保留日志空间来容纳此次调用的写入操作(像是一个判断能否开始操作的程序,不能就进入sleep)。
1 | |
log_write 充当 bwrite 的代理。它在内存中记录块的扇区编号,在磁盘上的日志中为其保留一个插槽,并将缓冲区固定在块缓存中以防止块缓存将其逐出。该块必须保留在缓存中直到提交:在此之前,缓存副本是修改的唯一记录;在提交后才能将其写入磁盘上的位置;并且同一事务中的其他读取必须看到修改。log_write 注意到在单个事务期间多次写入块时,并为该块在日志中分配相同的插槽。这种优化通常称为吸收。例如,在一个事务中多次写入包含几个文件的 inode 的磁盘块是很常见的。通过将多个磁盘写入吸收为一个,文件系统可以节省日志空间并获得更好的性能,因为只需将磁盘块的一个副本写入磁盘。
1 | |
end_op 及 commit 的代码:
1 | |
recover_from_log(kernel/log.c:117)从 initlog(kernel/log.c:55)调用。它读取日志头,如果头指示日志包含已提交事务,则模仿 end_op 的操作。 这就是可以在崩溃后使用日志恢复磁盘的相关操作。
1 | |
4.Code: Block allocator
文件和目录内容存储在磁盘块中,必须从空闲池中分配。Xv6 的块分配器在磁盘上维护一个空闲位图,每个块一位。零位表示相应的块是空闲的;一位表示它正在使用。程序 mkfs 设置与引导扇区、超级块、日志块、inode 块和位图块相对应的位。
1 | |
5.Inode layer
文件系统的核心数据结构就是 inode,“inode”可以有两个相关的含义之一。它可能指的是包含文件大小和数据块编号列表的磁盘上的数据结构。或者“inode”可能指的是内存中的 inode,它包含磁盘上 inode 的副本以及内核中需要的额外信息。
磁盘上的 inode 被打包到一个称为 inode 块的连续磁盘区域中。每个 inode 的大小相同,因此给定一个数字 n,很容易在磁盘上找到第 n 个 inode。实际上,这个数字 n,称为 inode 编号或 i-number,是在实现中识别 inode 的方式。类似的,我们也可以在知道某个字节的情况。
1 | |
磁盘上的 inode 由 struct dinode(kernel/fs.h:32)定义,具体代码如下:
1 | |
内核将活动 inode 的集合保存在一个称为 itable 的内存表中;struct inode(kernel/file.h:17)是磁盘上 struct dinode 的内存副本。内核仅在有 C 指针引用该 inode 时才将其存储在内存中。特别需要注意的是:ref 字段计算引用内存中 inode 的 C 指针的数量,如果引用计数降至零,内核将从内存中丢弃该 inode。对 inode 的指针可以来自文件描述符、当前工作目录和临时内核代码,如 exec。
1 | |
xv6 的 inode 代码中有四种锁或类似锁的机制。itable.lock 保护 inode 在 inode 表中最多出现一次的不变量,以及内存中 inode 的 ref 字段计算内存中指向该 inode 的指针数量的不变量。每个内存中的 inode 都有一个包含睡眠锁的 lock 字段,确保对 inode 的字段(如文件长度)以及 inode 的文件或目录内容块的独占访问。如果 inode 的 ref 大于零,则系统会将该 inode 保留在表中,而不会将表项重新用于不同的 inode。最后,每个 inode 都包含一个 nlink 字段(如果在内存中则在磁盘上并复制到内存中),该字段计算引用文件的目录项的数量;如果其链接计数大于零,xv6 不会释放该 inode。
iget()返回的 struct inode 指针保证在相应的 iput()调用之前是有效的;inode 不会被删除,指针所引用的内存也不会被用于不同的 inode:
1 | |
iget 返回的 struct inode 可能没有任何有用的内容。为了确保它持有磁盘上 inode 的副本,代码必须调用 ilock。这会锁定 inode(以便没有其他进程可以 ilock 它),并从磁盘读取 inode,如果尚未读取的话。iunlock 释放对 inode 的锁。将获取 inode 指针与锁定分开有助于在某些情况下避免死锁,例如在目录查找期间。多个进程可以持有对 iget 返回的 inode 的 C 指针,但一次只能有一个进程锁定该 inode。
1 | |
inode 表仅存储内核代码或数据结构持有 C 指针的 inode。它的主要工作是同步多个进程的访问。inode 表也恰好缓存经常使用的 inode, 但缓存是次要的;如果一个 inode 被频繁使用,缓冲区缓存可能会将其保留在内存中。修改内存中 inode 的代码使用 iupdate 将其写入磁盘。
要分配一个新的索引节点(例如,在创建文件时),xv6 会调用 ialloc(kernel/fs.c:199)。 ialloc 比较好理解就不在此单独列出, 它与 balloc 类似,逐个块地遍历磁盘上的索引节点结构,寻找一个标记为空闲的索引节点。当找到一个时,它会通过将新类型写入磁盘来占用它,然后通过尾调用 iget 从索引节点表中返回一个条目。
iput(kernel/fs.c:337)通过递减引用计数(kernel/fs.c:360)来释放对索引节点的 C 指针。如果这是最后一个引用,那么索引节点在索引节点表中的槽现在是空闲的,可以重新用于不同的索引节点。 如果 iput 发现没有对索引节点的 C 指针引用,并且索引节点没有与之相关的链接(不在任何目录中),则必须释放索引节点及其数据块。iput 调用 itrunc 将文件截断为零字节,释放数据块;将索引节点类型设置为 0(未分配);并将索引节点写入磁盘(kernel/fs.c:342)。
1 | |
6.Code: Inode content
磁盘上的索引节点结构,即struct dinode,包含一个大小和一个块号数组。索引节点数据位于dinode的addrs数组中列出的块中。前NDIRECT个数据块列在数组的前NDIRECT个条目中;这些块称为直接块。接下来的NINDIRECT个数据块不是列在索引节点中,而是列在一个称为间接块的数据块中。addrs数组的最后一个条目给出了间接块的地址。
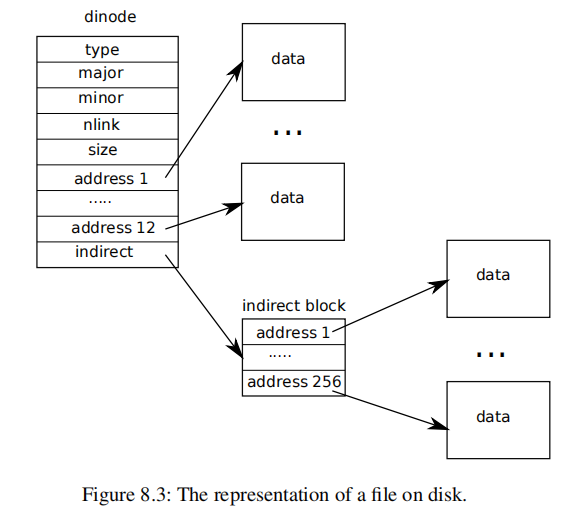
因此,文件的前 12 kB(NDIRECT x BSIZE)字节可以从索引节点中列出的块加载,而接下来的 256 kB(NINDIRECT x BSIZE)字节只能在查阅间接块后加载。这是一种良好的磁盘表示,但对客户端来说是一种复杂的表示。bmap函数管理这种表示,以便更高级的例程,如我们稍后将看到的readi和writei,不需要管理这种复杂性。bmap返回索引节点ip的第bn个数据块的磁盘块号。如果ip还没有这样的块,bmap会分配一个,以下是 bmap 的具体实现:
1 | |
itrunc释放文件的块,将索引节点的大小重置为零。itrunc(kernel/fs.c:426)首先释放直接块(kernel/fs.c:432-437),然后释放间接块中列出的块(kernel/fs.c:442-445),最后释放间接块本身(kernel/fs.c:447-448)。 bmap使readi和writei更容易获取索引节点的数据。readi(kernel/fs.c:472)首先确保偏移量和计数不超过文件的末尾。从文件末尾开始的读取会返回错误(kernel/fs.c:477-478),而从文件末尾或跨越文件末尾开始的读取会返回比请求的字节数少(kernel/fs.c:479-480)。主循环处理文件的每个块,将数据从缓冲区复制到dst(kernel/fs.c:482-494)。writei(kernel/fs.c:506)与readi相同,有三个例外:从文件末尾或跨越文件末尾开始的写入会增长文件,直到最大文件大小(kernel/fs.c:513-514);循环将数据复制到缓冲区而不是输出(kernel/fs.c:36);如果写入扩展了文件,writei必须更新其大小。
1 | |
stati函数(kernel/fs.c:458)将索引节点元数据复制到stat结构中,该结构通过stat系统调用暴露给用户程序。
6.Directory layer
目录在内部的实现方式与文件非常相似。它的 inode 具有类型 T_DIR,其数据是一个目录项序列。每个目录项都是一个 struct dirent(kernel/fs.h:56),其中包含一个名称和一个 inode 编号。名称最多为 DIRSIZ(14)个字符;如果较短,则以 NULL(0)字节结尾。inode 编号为零的目录项是空闲的。
1 | |
函数 dirlookup(内核/fs.c:552)在目录中搜索具有给定名称的条目。如果找到一个,它将返回一个指向相应 inode 的指针,该指针已解锁,并将 *poff 设置为目录内条目的字节偏移量,以防调用者希望编辑它。如果 dirlookup 找到具有正确名称的条目,它将更新 *poff 并返回通过 iget 获得的已解锁 inode。
1 | |
dirlookup 是 iget 返回已解锁 inode 的原因。调用者已经锁定了 dp,因此如果查找的是.,即当前目录的别名,尝试在返回之前锁定 inode 将尝试重新锁定 dp 并导致死锁。(还有更复杂的死锁场景涉及多个进程和..,即父目录的别名;.不是唯一的问题。)调用者可以解锁 dp,然后锁定 ip,确保它一次只持有一个锁。
函数 dirlink(内核/fs.c:580)将具有给定名称和 inode 编号的新目录项写入目录 dp 中。如果名称已经存在,dirlink 将返回错误(内核/fs.c:586-590)。主循环读取目录项,寻找未分配的条目。当找到一个时,它会提前停止循环(内核/fs.c:563-564),并将 off 设置为可用条目的偏移量。否则,循环结束时 off 将设置为 dp->size。无论哪种情况,dirlink 都会通过在偏移量 off 处写入来将新条目添加到目录中。
1 | |
7.Path names
路径名查找涉及对 dirlookup 的连续调用,每个路径组件调用一次。
namei(kernel/fs.c:687)评估路径并返回相应的 inode。函数 nameiparent 是一个变体:它在最后一个元素之前停止,返回父目录的 inode 并将最终元素复制到 name 中。两者都调用通用函数 namex 来完成实际工作。
1 | |
过程 namex 可能需要很长时间才能完成:它可能涉及几个磁盘操作来读取路径名中遍历的目录的 inode 和目录块(如果它们不在缓冲区缓存中)。Xv6 经过精心设计,以便如果一个内核线程对 namex 的调用被磁盘 I/O 阻塞,另一个内核线程查找不同的路径名可以同时进行。namex 分别锁定路径中的每个目录,以便在不同目录中的查找可以并行进行。
这种并发性带来了一些挑战。例如,当一个内核线程正在查找路径名时,另一个内核线程可能正在通过删除目录来更改目录树。一个潜在的风险是,可能正在搜索另一个内核线程已删除的目录,并且其块已被重新用于另一个目录或文件。
Xv6 避免了这种竞争。例如,在 namex 中执行 dirlookup 时,查找线程持有目录的锁,dirlookup 返回使用 iget 获取的 inode。iget 增加了 inode 的引用计数。只有在从 dirlookup 接收到 inode 后,namex 才释放目录的锁。现在另一个线程可以从目录中删除 inode,但 xv6 不会立即删除 inode,因为 inode 的引用计数仍然大于零。
另一个风险是死锁。例如,在查找“.”时,next 指向与 ip 相同的 inode。在释放 ip 的锁之前锁定 next 将导致死锁。为了避免这种死锁,namex 在获取 next 的锁之前解锁目录。在这里,我们再次看到了 iget 和 ilock 分离的重要性。
8.File descriptor layer
Unix 接口的一个很酷的方面是,Unix 中的大多数资源都表示为文件,包括控制台、管道等设备,当然还有真正的文件。文件描述符层是实现这种统一性的层。
正如我们在第 1 章中看到的,Xv6 为每个进程提供了自己的打开文件表,或文件描述符。每个打开的文件都由一个 struct file(kernel/file.h:1)表示,它是围绕一个 inode 或管道的包装器,加上一个 I/O 偏移量。每次调用 open 都会创建一个新的打开文件(一个新的 struct file):如果多个进程独立地打开同一个文件,不同的实例将具有不同的 I/O 偏移量。另一方面,单个打开文件(同一个 struct file)可以在一个进程的文件表中多次出现,也可以在多个进程的文件表中出现。如果一个进程使用 open 打开文件,然后使用 dup 创建别名,或者使用 fork 与子进程共享,就会发生这种情况。一个引用计数跟踪对特定打开文件的引用次数。文件可以打开用于读取或写入,或者同时用于两者。可读和可写字段跟踪这一点。
1 | |
系统中的所有打开文件都保存在一个全局文件表 ftable 中。文件表具有分配文件(filealloc)、创建重复引用(filedup)、释放引用(fileclose)以及读取和写入数据(fileread 和 filewrite)的函数。
前三个函数遵循现在熟悉的形式。filealloc(内核/file.c:30)扫描文件表以查找未引用的文件(f->ref == 0)并返回一个新的引用;filedup(内核/file.c:48)增加引用计数;fileclose(内核/file.c:60)减少它。当文件的引用计数达到零时,fileclose 根据类型释放底层管道或 inode。
函数 filestat、fileread 和 filewrite 实现了对文件的 stat、read 和 write 操作。filestat(kernel/file.c:88)仅允许在 inodes 上调用,并调用 stati。fileread 和 filewrite 检查操作是否被打开模式允许,然后将调用传递给管道或 inode 实现。如果文件表示一个 inode,fileread 和 filewrite 使用 I/O 偏移量作为操作的偏移量,然后推进它(内核/file.c:122-123)(内核/file.c:153-154)。管道没有偏移量的概念。回想一下,inode 函数要求调用者处理锁定(内核/file.c:94-96)(内核/file.c:121-124)(内核/file.c:163-166)。inode 锁定具有方便的副作用,即读和写偏移量是原子地更新的,因此同时对同一文件的多次写入不会覆盖彼此的数据,尽管它们的写入可能最终交织在一起。
9.System calls
利用底层提供的功能,大多数系统调用的实现都很简单(见(kernel/sysfile.c))。有几个调用值得仔细研究。
函数 sys_link 和 sys_unlink 编辑目录,创建或删除对 inode 的引用。它们是使用事务的另一个很好的例子。sys_link(kernel/sysfile.c:124)首先获取其参数,两个字符串 old 和 new(kernel/sysfile.c:133-136)。假设 old 存在且不是目录(kernel/sysfile.c:133-136),sys_link 递增其 ip->nlink 计数。然后 sys_link 调用 nameiparent 来查找 new 的父目录和最终路径元素(kernel/sysfile.c:149),并创建一个指向 old 的 inode 的新目录项(kernel/sysfile.c:152)。新的父目录必须存在并且与现有 inode 在同一设备上:inode 编号在单个磁盘上才有唯一的意义。如果发生这样的错误,sys_link 必须返回并递减 ip->nlink。
1 | |
事务简化了实现,因为它需要更新多个磁盘块,但我们不必担心执行它们的顺序。它们要么全部成功,要么全部失败。例如,没有事务,在创建链接之前更新 ip->nlink,会使文件系统暂时处于不安全状态,而在此期间的崩溃可能会导致严重破坏。有了事务,我们就不必担心这个问题。
sys_link 为现有的 inode 创建一个新名称。函数 create(kernel/sysfile.c:246)为新的 inode 创建一个新名称。它是三个文件创建系统调用的泛化:使用 O_CREATE 标志的 open 创建一个新的普通文件,mkdir 创建一个新的目录,mkdev 创建一个新的设备文件。与 sys_link 一样,create 首先调用 nameiparent 来获取父目录的 inode。然后它调用 dirlookup 来检查该名称是否已经存在(kernel/sysfile.c:256)。如果该名称确实存在,则 create 的行为取决于它正在用于哪个系统调用:open 与 mkdir 和 mkdev 的语义不同。如果 create 正在代表 open(type == T_FILE)使用,并且存在的名称本身是一个常规文件,那么 open 将其视为成功,因此 create 也这样做(kernel/sysfile.c:260)。
否则,这是一个错误(kernel/sysfile.c:261-262)。如果该名称不存在,create 现在使用 ialloc 分配一个新的 inode(kernel/sysfile.c:265)。如果新的 inode 是一个目录,create 使用.和..条目对其进行初始化。最后,现在数据已正确初始化,create 可以将其链接到父目录中(kernel/sysfile.c:278)。create,与 sys_link 一样,同时持有两个 inode 锁:ip 和 dp。由于 inode ip 是新分配的,因此不存在死锁的可能性:系统中的其他进程不会持有 ip 的锁,然后尝试锁定 dp。使用 create,可以很容易地实现 sys_open、sys_mkdir 和 sys_mknod。sys_open(kernel/sysfile.c:305)是最复杂的,因为创建一个新文件只是它可以做的一小部分。如果 open 传递了 O_CREATE 标志,它将调用 create(kernel/sysfile.c:320)。否则,它将调用 namei(kernel/sysfile.c:326)。create 返回一个锁定的 inode,但 namei 没有,因此 sys_open 必须自己锁定 inode。这提供了一个方便的位置来检查目录是否仅以只读方式打开,而不是写入。假设以某种方式获取了 inode,sys_open 分配一个文件和一个文件描述符(kernel/sysfile.c:344),然后填充文件(kernel/sysfile.c:356-361)。请注意,由于它仅在当前进程的表中,因此没有其他进程可以访问部分初始化的文件。
第 7 章在我们甚至还没有文件系统之前就研究了管道的实现。函数 sys_pipe 通过提供创建管道对的方法将该实现与文件系统连接起来。它的参数是一个指向两个整数空间的指针,它将在其中记录两个新的文件描述符。然后它分配管道并安装文件描述符。
15.实际情况
真实世界中的操作系统的缓冲区缓存比 xv6 的要复杂得多,但它有两个相同的目的:缓存和同步对磁盘的访问。Xv6 的缓冲区缓存使用简单的最近最少使用(LRU)淘汰策略;还有许多更复杂的策略可以实现,每种策略都适用于某些工作负载,而不适用于其他工作负载。更高效的 LRU 缓存将消除链表,而是使用哈希表进行查找和堆进行 LRU 淘汰。现代缓冲区缓存通常与虚拟内存系统集成,以支持内存映射文件。
Xv6 的日志系统效率低下。提交不能与文件系统系统调用同时发生。系统记录整个块,即使在一个块中只有几个字节发生了变化。它执行同步日志写入,一次一个块,每个块都可能需要整个磁盘旋转时间。真正的日志系统解决了所有这些问题。同时日志不是提供崩溃恢复的唯一方法。
Xv6 使用与早期 UNIX 相同的基本磁盘上的 inode 和目录布局。文件系统布局中最效率低下的部分是目录,它在每次查找时都需要对所有磁盘块进行线性扫描。当目录只有几个磁盘块时,这是合理的,但对于包含许多文件的目录来说,这是十分低效的。
Xv6 要求文件系统适合一个磁盘设备,并且大小不能改变。随着大型数据库和多媒体文件推动存储需求不断提高,操作系统正在开发方法来消除“每个文件系统一个磁盘”的瓶颈。基本方法是将许多磁盘组合成一个逻辑磁盘。硬件解决方案,如 RAID,仍然是最受欢迎的,但当前的趋势是尽可能在软件中实现更多的这种逻辑。
Xv6 的文件系统缺少现代文件系统的许多其他功能;例如,它缺少对快照和增量备份的支持。 现代 Unix 系统允许使用与磁盘存储相同的系统调用访问许多种资源:命名管道、网络连接、远程访问的网络文件系统以及监控和控制接口等等。
1.Large files ()
在这个实验中,将增加 xv6 文件的最大大小。目前,xv6 文件被限制为 268 个块,即 268*BSIZE 字节(在 xv6 中,BSIZE 为 1024)。这个限制来自于 xv6 中的 inode 包含 12 个“直接”块号和一个“单间接”块号,后者指的是一个块,最多可容纳 256 个更多的块号,总共 12+256=268 个块。
实验内容:更改 xv6 文件系统代码,以在每个 inode 中支持一个“双间接”块,其中包含 256 个单间接块的地址,每个单间接块最多可以包含 256 个数据块的地址。结果是,一个文件将能够由多达 65803 个块组成,即 256*256+256+11 个块(11 而不是 12,因为我们将为双间接块牺牲一个直接块号)。
mkfs 程序创建 xv6 文件系统磁盘映像,并确定文件系统总共有多少个块;这个大小由 kernel/param.h 中的 FSSIZE 控制。你会看到这个实验室的存储库中的 FSSIZE 设置为 200,000 个块。应该在 make 输出中看到 mkfs/mkfs 的以下输出:
1 | |
这一行描述了 mkfs/mkfs 构建的文件系统:它有 70 个元数据块(用于描述文件系统的块)和 199,930 个数据块,总共 200,000 个块。 如果在实验时需要从头开始重建文件系统,可以运行 make clean,这将强制 make 重新构建 fs.img。
仔细审题,目前的 inode 应该由 11 个直接块(对应NDIRECT,共11个块),1个单间接块(对应NINDIRECT,共256块)和一个双间接块(新建一个宏定义,DBLDIRECT,共256*256块)才能达到题目要求。
磁盘上 inode 的格式由 fs.h 中的 struct dinode 定义。我们需要对 NDIRECT、NINDIRECT、MAXFILE 和 struct dinode 的 addrs[]等元素进行修改。更改 NDIRECT 的定义,同时需要更改 file.h 中 struct inode 中 addrs[]的声明。确保 struct inode 和 struct dinode 在其 addrs[]数组中具有相同数量的元素。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36// 最先修改的是 NDIRECT(kernel/fs.h:27)
// 原先是12,现在把一个直接块要改成双间接块,所以减去1
#define NDIRECT 11
// 添加一个DBLDIRECT,对应双间接块数量
#define DBLDIRECT 256*256
// 添加了块数量,对应的MAXFILE也要修改
#define MAXFILE (NDIRECT + NINDIRECT + DBLDIRECT)
// 然后对struct dinode进行修改
struct dinode {
short type;
short major;
short minor;
short nlink;
uint size;
// 块索引外的其它参数不进行修改
// 由于NDIRECT少了1,这里修改成+2
uint addrs[NDIRECT+2]; // Data block addresses
};
// 一样的修改
struct inode {
uint dev;
uint inum;
int ref;
struct sleeplock lock;
int valid;
short type;
short major;
short minor;
short nlink;
uint size;
uint addrs[NDIRECT+2];
};修改 bmap(),使其除了直接块和单间接块之外,还实现了一个双间接块。为了给新的双间接块腾出空间,你只能有 11 个直接块,而不是 12 个;你不允许更改磁盘上 inode 的大小。ip->addrs[]的前 11 个元素应该是直接块;第 12 个应该是单间接块(就像当前的一样);第 13 个应该是你的新双间接块。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84static uint
bmap(struct inode *ip, uint bn)
{
uint addr, *a;
struct buf *bp;
// 如果块号小于 NDIRECT,这部分是给直接块分配
// 我们不修改此处
if (bn < NDIRECT) {
if ((addr = ip->addrs[bn]) == 0) {
addr = balloc(ip->dev);
if (addr == 0)
return 0;
ip->addrs[bn] = addr;
}
return addr;
}
// 如果bn不在直接块中,就要计算它的位置
// 先减去直接块的数量
bn -= NDIRECT;
// 如果块号小于 NINDIRECT,说明它在单间接块中
if (bn < NINDIRECT) {
// 加载间接块,必要时分配
if ((addr = ip->addrs[NDIRECT]) == 0) {
addr = balloc(ip->dev);
if (addr == 0)
return 0;
ip->addrs[NDIRECT] = addr;
}
bp = bread(ip->dev, addr);
a = (uint*)bp->data;
if ((addr = a[bn]) == 0) {
addr = balloc(ip->dev);
if (addr) {
a[bn] = addr;
log_write(bp);
}
}
brelse(bp);
return addr;
}
// 代码运行到此处就只有两种可能性
// 第一种是该块在双间接块中,第二种是参数bn越界了
// 先计算其在双间接块中的位置
bn -= NINDIRECT;
if (bn < DBLDIRECT) {
// 加载间接块,必要时分配
// 这里需要修改下标,对应双间接块
if ((addr = ip->addrs[NDIRECT+1]) == 0) {
addr = balloc(ip->dev);
if (addr == 0)
return 0;
ip->addrs[NDIRECT+1] = addr;
}
bp = bread(ip->dev, addr);
a = (uint*)bp->data;
// 这里开始对双间接块进行操作
// 本质上就是把原来的 bmap 的对应部分重复两遍
// 理解成先找双间接块中bn下标对应的单间接块
int index = bn / NINDIRECT;
bn = bn % NINDIRECT;
if ((addr = a[index]) == 0) {
addr = balloc(ip->dev);
if (addr) {
a[bn] = addr;
log_write(bp);
}
}
brelse(bp);
bp = bread(ip->dev, addr);
a = (uint*)bp->data;
// 在对应的单间接块中找到下标为bn的即可
if ((addr = a[bn]) == 0) {
addr = balloc(ip->dev);
if (addr) {
a[bn] = addr;
log_write(bp);
}
}
brelse(bp);
return addr;
}
// 运行到此处说明参数越界,进入panic
panic("bmap: out of range");
}修改 itrunc 以释放文件的所有块,包括双间接块。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57void
itrunc(struct inode *ip)
{
// 双间接快的释放需要两层循环
// 提前定义好相关的变量
int i, j, k;
struct buf *bp,*dblbp;
uint *a,*b;
// 释放直接块,不需要进行修改
for (i = 0; i < NDIRECT; i++) {
if (ip->addrs[i]) {
bfree(ip->dev, ip->addrs[i]);
ip->addrs[i] = 0;
}
}
// 释放单间接块,也不需要进行修改
if (ip->addrs[NDIRECT]) {
bp = bread(ip->dev, ip->addrs[NDIRECT]);
a = (uint*)bp->data;
for (j = 0; j < NINDIRECT; j++) {
if (a[j]) {
bfree(ip->dev, a[j]);
}
}
brelse(bp);
bfree(ip->dev, ip->addrs[NDIRECT]);
ip->addrs[NDIRECT] = 0;
}
// 释放双间接块
if (ip->addrs[NDIRECT+1]) {
bp = bread(ip->dev, ip->addrs[NDIRECT+1]);
a = (uint*)bp->data;
for (j = 0; j < NINDIRECT; j++) {
// 前面按部就班获取,这里不一样在
// a[j]可以理解成一个单间接块
if (a[j]) {
dblbp = bread(ip->dev, a[j]);
b = (uint*)dblbp->data;
// 遍历每个块,若有需要就释放
for (k = 0; k < NINDIRECT; k++) {
if (b[k]) {
bfree(ip->dev, b[k]);
}
}
brelse(dblbp);
bfree(ip->dev,a[j]);
}
}
brelse(bp);
bfree(ip->dev, ip->addrs[NDIRECT+1]);
ip->addrs[NDIRECT] = 0;
}
ip->size = 0;
iupdate(ip);
}
2.Symbolic links ()
本实验将向 xv6 添加符号链接。符号链接通过路径名引用链接文件;当打开符号链接时,内核会跟随链接到引用的文件。符号链接类似于硬链接,但硬链接仅限于指向同一磁盘上的文件,而符号链接可以跨越磁盘设备。尽管 xv6 不支持多个设备,但实现此系统调用是了解路径名查找工作原理的一个很好的练习。
符号链接,硬链接和软链接:硬链接和符号链接详解-CSDN博客
实验内容:实现 symlink(char *target, char *path) 系统调用,该调用在路径处创建一个新的符号链接,该链接引用由目标命名的文件。要进行测试,
首先,为 symlink 创建一个新的系统调用号,在 user/usys.pl、user/user.h 中添加一个条目,并在 kernel/sysfile.c 中实现一个空的 sys_symlink。(和添加新的系统调用流程相同,除提示外还得修改 kernel/syscall.c 和 kernel/syscall.h)。最后我们还需要把测试文件 symlinktest 添加到 Makefile 中并运行它。
在 kernel/stat.h 中添加一个新的文件类型(T_SYMLINK)来表示符号链接。
1
2// kernel/stat.h
#define T_SYMLINK 4 // Symbolic links在 kernel/fcntl.h 中添加一个新的标志(O_NOFOLLOW),该标志可与 open 系统调用一起使用。请注意,传递给 open 的标志使用按位或运算符组合,因此你的新标志不应与任何现有标志重叠。
1
2// kernel/fcntl.h
#define O_NOFOLLOW 0x800实现 symlink(target, path)系统调用,在 path 处创建一个新的符号链接,该链接引用 target。请注意,target 不需要存在以使系统调用成功。你需要选择一个地方来存储符号链接的目标路径,例如,在 inode 的数据块中。symlink 应该返回一个整数,表示成功(0)或失败(-1),类似于 link 和 unlink。 实现系统调用我们可以参考官方文档中介绍的 syslink 这个系统调用,虽然内容不同,但是整体结构是类似的。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39int
sys_symlink(){
struct inode *ip;
// 因为这是一个系统调用,我们从寄存器中获取参数
// 所以这里定义两个字符数组用于存储参数
char target[MAXPATH], path[MAXPATH];
// 获取参数,失败返回-1
if (argstr(0, target, MAXPATH) < 0 || argstr(1, path, MAXPATH) < 0)
return -1;
// 涉及日志操作
begin_op();
// 可以简单理解成以下两个操作
// 然后新建一个文件类型为 T_SYMLINK 的软链接文件
// 并让它指向刚才读取出来的 inode
// 创建文件类型为 T_SYMLINK 的软链接文件
if ((ip = create(path, T_SYMLINK, 0, 0) )== 0) {
end_op();
return -1;
}
// writei 将数据写入 inode
// 如果返回值小于请求的 n,则存在某种错误
// 所以我们为了验证它是否正确写入,就先获取target的长度
int n = strlen(target);
if (writei(ip, 0, (uint64)target, 0, n) != n) {
iunlockput(ip);
end_op();
return -1;
}
// 运行到这里已经正确写入
// create函数返回的inode持有锁,这里需要特别注意,将锁释放
iunlockput(ip);
end_op();
return 0;
}修改 open 系统调用以处理路径引用符号链接的情况。如果文件不存在,open 必须失败。当进程在 open 的标志中指定 O_NOFOLLOW 时,open 应该打开符号链接(而不是跟随符号链接)。 如果链接的文件也是符号链接,你必须递归地跟随它,直到到达非链接文件。如果链接形成一个循环,你必须返回一个错误代码。可以通过在链接的深度达到某个阈值(MAXDEPTH,10)时返回错误代码来近似实现。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96#define MAXDEPTH 10
uint64
sys_open(void)
{
char path[MAXPATH];
int fd, omode;
struct file *f;
struct inode *ip;
int n;
argint(1, &omode);
if((n = argstr(0, path, MAXPATH)) < 0)
return -1;
begin_op();
// 打开模式为CREATE,这部分可以用作参考
if(omode & O_CREATE){
ip = create(path, T_FILE, 0, 0);
if(ip == 0){
end_op();
return -1;
}
} else {
if((ip = namei(path)) == 0){
end_op();
return -1;
}
ilock(ip);
if(ip->type == T_DIR && omode != O_RDONLY){
iunlockput(ip);
end_op();
return -1;
}
}
// lab9_2 在此之前除宏定义外不做改动
// 在while循环中要记录递归深度
int depth = 0;
// 在打开模式为 O_NOFOLLOW 前不断递归
while(ip->type == T_SYMLINK && !(omode & O_NOFOLLOW)){
// 从符号链接中读取目标路径
if(readi(ip, 0, (uint64)path, 0, MAXPATH) < 0){
// 读取失败解锁并释放 inode 并结束文件操作
iunlockput(ip);
end_op();
return -1;
}
iunlockput(ip);
// 根据目标路径获取 inode
if((ip = namei(path)) == 0){
end_op();
return -1;
}
ilock(ip);
depth++;
// 如果深度超过 10,则解锁并释放 inode,结束文件操作,返回 -1
if(depth > MAXDEPTH){
iunlockput(ip);
end_op();
return -1;
}
}
// lab9_2 在此之后不做改动
if(ip->type == T_DEVICE && (ip->major < 0 || ip->major >= NDEV)){
iunlockput(ip);
end_op();
return -1;
}
if((f = filealloc()) == 0 || (fd = fdalloc(f)) < 0){
if(f)
fileclose(f);
iunlockput(ip);
end_op();
return -1;
}
if(ip->type == T_DEVICE){
f->type = FD_DEVICE;
f->major = ip->major;
} else {
f->type = FD_INODE;
f->off = 0;
}
f->ip = ip;
f->readable = !(omode & O_WRONLY);
f->writable = (omode & O_WRONLY) || (omode & O_RDWR);
if((omode & O_TRUNC) && ip->type == T_FILE){
itrunc(ip);
}
iunlock(ip);
end_op();
return fd;
}make grade成绩测试结果![image.png]()