xv6学习,Lab1-Xv6 and Unix utilities
Xv6是一个由MIT开发的用于操作系统课程教学的类Unix系统。
Lab1: Xv6 and Unix utilities
1. Boot xv6 (easy)
按照https://pdos.csail.mit.edu/6.828/2023/xv6.html官方文档中的“Tools Used in 6.1810”和知乎专栏https://zhuanlan.zhihu.com/p/632281381中的步骤配置好了xv6的相关环境。具体步骤如下:
在VMWare中安装Ubuntu 22.04 LTS,并安装
open-vm-tools等工具并设置共享文件夹方便未来学习。同时更改数据源,解决yml无法使用的问题。安装qemu5.1.0并克隆xv6源码仓库,这里使用的仓库是
git://g.csail.mit.edu/xv6-labs-2023。执行相关操作,启动xv6。按下Ctrl+A后再按X退出。
These are the files that mkfs includes in the initial file system; most are programs you can run. You just ran one of them: ls.
2. sleep (easy)
Implement a user-level
sleepprogram for xv6, along the lines of the UNIX sleep command. Yoursleepshould pause for a user-specified number of ticks. A tick is a notion of time defined by the xv6 kernel, namely the time between two interrupts from the timer chip. Your solution should be in the fileuser/sleep.c.
提示信息要求阅读book-riscv-rev1.pdf的Chapter1 Operating system interfaces(p9-p20),其核心内容如下:
操作系统的简介
对操作系统,接口,内核,shell等进行了简单介绍,”An operating system manages and abstracts the low-level hardware”,操作系统管理和抽象低级硬件,为程序的交互提供方式,以便它们可以共享数据或一起工作。“An operating system provides services to user programs through an interface”,操作系统通过接口向用户程序提供服务。xv6采用了内核的传统形式,这是一种为正在运行中的程序提供服务的特殊程序。每个正在运行的程序,称为进程,都有包含指令、数据和堆栈的内存。一个给定的计算机通常有许多进程,但只有一个内核。当进程需要调用内核服务时,它会调用系统调用,这是操作系统接口中的调用之一。系统调用进入内核;内核执行服务并返回。Shell是操作系统的最外层,负责管理和控制进程和文件,以及启动和控制其他程序。
进程和内存
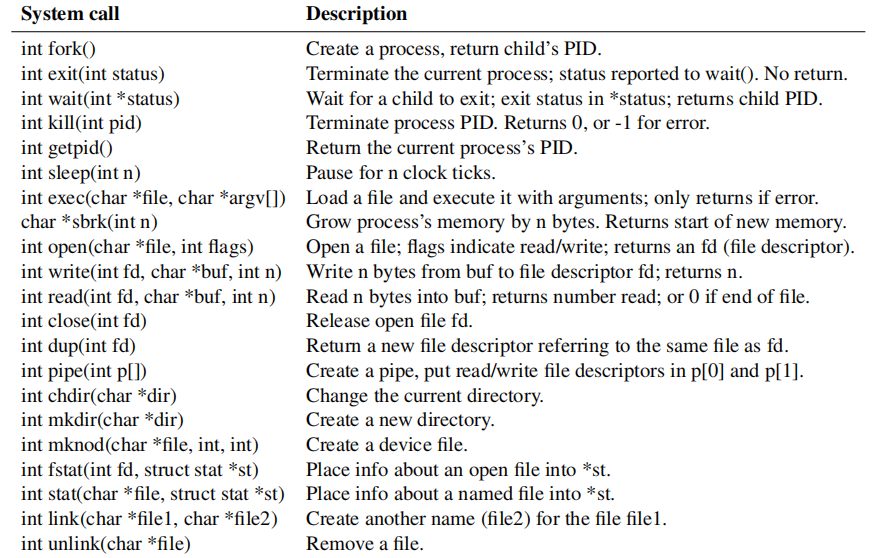
xv6进程由用户-空间内存(指令、数据和堆栈)和内核私有的每个进程状态组成。一个进程可以使用fork系统调用创建一个新的进程,子进程会返回0,父进程会返回子进程的PID。下图是所有的系统调用。
![image1_2.png]()
以下是一些代码实例,用于说明上面部分系统调用。
1
2
3
4
5
6
7
8
9
10
11int pid = fork();//创建子进程,此时父进程的值为子进程的pid,子进程值为0
if (pid > 0) {//父进程
printf("parent: child=%d\n", pid);//父进程输出子进程pid
pid = wait((int *) 0);//等待子进程退出,并返回子进程的pid
printf("child %d is done\n", pid);
} else if (pid == 0) {//子进程
printf("child: exiting\n");
exit(0);//结束子进程
} else {
printf("fork error\n");
}1
2
3
4
5
6char *argv[3];//参数数组
argv[0] = "echo";
argv[1] = "hello";
argv[2] = 0;//参数结束标志
exec("/bin/echo", argv);//调用exec函数执行"/bin/echo",并传递argv作为参数列表
printf("exec error\n");//调用失败输出错误信息The xv6 shell uses the above calls to run programs on behalf of users. The main structure of the shell is simple; see main (user/sh.c:145). The main loop reads a line of input from the user with
getcmd. Then it calls fork, which creates a copy of the shell process. The parent calls wait, while the child runs the command. For example, if the user had typed “echo hello” to the shell,runcmdwould have been called with “echo hello” as the argument.runcmd(user/sh.c:58) runs the actual command. For “echo hello”, it would call exec (user/sh.c:78). If exec succeeds then the child will execute instructions from echo instead ofruncmd. At some point echo will call exit, which will cause the parent to return from wait in main (user/sh.c:145).xv6 shell利用上述调用来代表用户运行程序。shell的主要结构较为简单;如user/sh.c:145 main函数所示。主循环用
getcmd从用户那里读取一行输入数据。然后它调用 fork,从而创建一个shell进程的复制体。当子节点运行该命令时,父节点调用等待命令。例如,如果用户向shell输入“echo hello”,runcmd将以“echo hello”作为参数。runcmd(user/sh.c:58)运行实际的命令。对于“echo hello”,它将调用exec(user/sh.c:78)。如果exec成功,那么子进程将从echo而不是runcmd执行指令。在某个点上,echo将调用exit,这将导致父节点从主节点(user/sh.c:145)中的等待中返回。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26//user/sh.c:145
int main(void) {
static char buf[100];// 分配大小为100的静态字符数组作为输入缓冲区
int fd;
// 确保有三个文件描述符打开
while ((fd = open("console", O_RDWR)) >= 0) { //以读写模式O_RDWR进行打开,文件描述符被存储在变量fd中
if (fd >= 3) {
close(fd);
break;
}
}
// 读取和运行输入的命令
while (getcmd(buf, sizeof(buf)) >= 0) {
if (buf[0] == 'c' && buf[1] == 'd' && buf[2] == ' ') {//如果命令是cd,则切换目录
// chdir必须被父进程调用,而不是子进程
buf[strlen(buf) - 1] = 0; // 去掉末尾的换行符
if (chdir(buf + 3) < 0)//如果切换目录失败,则输出错误信息
fprintf(2, "cannot cd %s\n", buf + 3);
continue;//不执行之后的代码,直接继续读取输入的命令
}
if (fork1() == 0)//子进程
runcmd(parsecmd(buf));//解析并执行用户输入的命令
wait(0);//等待子进程结束
}
exit(0);//结束程序
}I/O和文件描述符
A file descriptor is a small integer representing a kernel-managed object that a process may read from or write to. A process may obtain a file descriptor by opening a file, directory, or device, or by creating a pipe, or by duplicating an existing descriptor.
文件描述符是一个小整数,表示进程可以从中读取或写入的内核管理对象。进程可以通过打开文件、目录或设备,或通过创建管道,或通过复制现有的描述符来获取文件描述符。
简而言之,进程从文件描述符0读取,将输出写入文件描述符1,并将错误消息写入文件描述符2。下面是一些相关的系统调用和例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19read(fd, buf, n);//从文件描述符 fd 读取n个字节到buf中
write(fd, buf, n);//从buf写入n个字节到文件描述符fd,并返回写入的字节数
//程序cat:这是一段从标准输入读入,并将读入的内容写入标准输出,直到遇到输入末尾停止的代码
char buf[512];//标准输入缓冲区,暂存内容
int n;
for(;;){
n = read(0, buf, sizeof buf);//从标准输入读取数据,存储在buf中
if(n == 0)//如果为0,说明读取到了末尾,退出循环
break;
if(n < 0){//如果为负数,说明出现错误,输出错误信息
fprintf(2, "read error\n");
exit(1);
}
if(write(1, buf, n) != n){//将读取的数据写入标准输出,若等于n继续,不等于n说明出错
fprintf(2, "write error\n");//输出错误信息
exit(1);
}
}File descriptors and fork interact to make I/O redirection easy to implement.
文件描述符和fork结合,使I/O重定向易于实现。
1
2
3
4
5
6
7
8
9//PDF中的样例代码
char *argv[2];
argv[0] = "cat";
argv[1] = 0;
if(fork() == 0) {//子进程
close(0);//关闭文件描述符0
open("input.txt", O_RDONLY);//打开的input.txt的文件描述符,此时0将是最小的可用文件描述符
exec("cat", argv);
}The code for I/O redirection in the xv6 shell works in exactly this way (user/sh.c:82).
(user/sh.c:82)中xv6 shell中的输入输出重定向就是通过上述代码的方式实现的。
1
2
3
4
5
6
7
8
9
10//user/sh.c:82 runcmd对cmd的type进行switch,当type为REDIR时的代码如下,实现重定向
case REDIR:
rcmd = (struct redircmd*)cmd;// 强制转换为rcmd类型
close(rcmd->fd);// 关闭重定向文件描述符
if (open(rcmd->file, rcmd->mode) < 0) {// 以mode模式打开结构体中的file文件,并验证是否打开成功
fprintf(2, "open %s failed\n", rcmd->file); //失败输出错误信息
exit(1);
}
runcmd(rcmd->cmd);// 递归调用runcmd函数,执行重定向命令中的子命令
break;管道
用于进程间通信。下面是示例代码。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17int p[2];//用于存储管道的读写文件描述符
char *argv[2];//参数
argv[0] = "wc";//只有一个参数“wc”
argv[1] = 0;
pipe(p);//调用pipe(p)创建一个管道,其中p[0]用于读取,p[1]用于写入
if (fork() == 0) {//子进程
close(0);//关闭标准输入文件描述符0
dup(p[0]);//将管道的读取文件描述符复制到0,子进程的标准输入就被重定向到管道的读取端
close(p[0]);
close(p[1]);
exec("/bin/wc", argv);//调用exec函数执行"/bin/wc"程序,使用argv作为参数列表
//这里wc本身应该从标准输入中读取,经过上面的重定向,将从管道中读取
} else {//父进程
close(p[0]);//关闭p[0]读取端,父进程在此段代码中只需要写入
write(p[1], "hello world\n", 12);//向管道中写入字符串
close(p[1]);//写入操作已完成,关闭p[1]
}If no data is available, a read on a pipe waits for either data to be written or for all file descriptors referring to the write end to be closed; in the latter case, read will return 0, just as if the end of a data file had been reached. The fact that read blocks until it is impossible for new data to arrive is one reason that it’s important for the child to close the write end of the pipe before executing wc above: if one of wc ’s file descriptors referred to the write end of the pipe, wc would never see end-of-file.
在上面的代码片段中,缓冲区没有数据时,对管道的读取端将等待直到数据被写入或者所有管道写入端的文件描述符被关闭。只有将子进程和父进程的写入端全部关闭,读取端才会读到长度为0的数据,否则将会造成阻塞。
The xv6 shell implements pipelines such as grep fork sh.c | wc -l in a manner similar to the above code (user/sh.c:100).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24//user/sh.c:100
case PIPE:
pcmd = (struct pipecmd*)cmd; // 将cmd强制转换为pipecmd结构体类型
if (pipe(p) < 0) // 创建管道,p[0]用于读取,p[1]用于写入
panic("pipe"); // 如果创建失败,则触发panic,输出错误信息并结束进程
if (fork1() == 0) { // 创建第一个子进程
close(1); // 关闭标准输出
dup(p[1]); // 将标准输出重定向到p[1]
close(p[0]); // 关闭p[0]和p[1]
close(p[1]);
runcmd(pcmd->left); // 在第一个子进程中执行左侧命令
}
if (fork1() == 0) { // 创建第二个子进程
close(0); // 关闭标准输入
dup(p[0]); // 将标准输入重定向到p[0]
close(p[0]); // p[0]和p[1]
close(p[1]);
runcmd(pcmd->right); // 在第二个子进程中执行右侧命令
}
close(p[0]); // 关闭父进程p[0]
close(p[1]); // 关闭父进程p[1]
wait(0); // 等待子进程1退出
wait(0); // 等待子进程2退出
break;Pipes may seem no more powerful than temporary files: the pipeline
echo hello world | wc
could be implemented without pipes as
echo hello world >/tmp/xyz; wc </tmp/xyz
echo hello world | wc使用管道,将”hello world”字符串通过echo命令传递给wc命令,而echo hello world >/tmp/xyz; wc </tmp/xyz将”hello world”字符串输出到一个临时文件/tmp/xyz中,然后将这个临时文件作为输入给wc命令。这种方法虽然也能达到相同的目的,但需要额外创建和管理临时文件,增加了额外的复杂性和开销。管道的四个优势:
- 管道可以自动清理,而临时文件需要shell清理。
- 管道可以通过任意长的数据流,而使用临时文件需要在磁盘上有足够的空间来存储数据。
- 管道允许按照阶段来并行执行,而文件方法要求第一个程序在第二个程序启动之前完成。
- 如果需要实现进程间通信,那么管道的阻塞读取和写操作比文件的非阻塞语义更有效。
文件系统(File System)
xv6文件系统提供了数据文件,包括未解释的字节数组,对数据文件和其他目录的命名引用的目录。Xv6将目录视为一种特殊的文件,目录树从一个被叫做root的特殊目录开始。
1
2
3
4
5chdir("/a");//切换到目录/a
chdir("b");//切换到目录/a/b
open("c", O_RDONLY);
open("/a/b/c", O_RDONLY);//和上面三行作用相同,但是不需要改变目录mkdir命令用于创建新目录,open命令使用O_CREATE标志则是创建新的数据文件,而mknod则创建了一个引用一个设备的特殊文件,其拥有两个参数,主要设备编号和次要设备编号,它们唯一地标识了一个内核设备,下为示例:1
2
3
4
5mkdir("/dir"); // 创建名为"/dir"的新目录
fd = open("/dir/file", O_CREATE|O_WRONLY);// 创建file文件,以只写形式打开,保存文件描述符到fd中
close(fd);
mknod("/console", 1, 1);文件的名称与文件本身不同;相同的底层文件,称为
inode,可以有多个名称,称为link。每个link由一个目录中的一个条目组成;该条目包含一个文件名和一个对inode的引用。inode保存有关文件的元数据,包括它的类型(文件或目录或设备)、它的长度、文件内容在磁盘上的位置以及到文件的链接数量。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15#define T_DIR 1 // Directory
#define T_FILE 2 // File
#define T_DEVICE 3 // Device
struct stat {
int dev; // File system’s disk device
uint ino; // Inode number
short type; // Type of file
short nlink; // Number of links to file
uint64 size; // Size of file in bytes
};
The link system call creates another file system name referring to the same inode as an existing file. This fragment creates a new file named both a and b.
open("a", O_CREATE|O_WRONLY);//创建文件a
link("a", "b");//将文件a和b链接起来
unlink("a");//取消a的链接
阅读 user/echo.c, user/grep.c, and user/rm.c 了解命令行参数如何传递给程序,之后在 user/sleep.c中完成相关代码。
以
user/echo.c为例,了解参数传递1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
int
main(int argc, char *argv[])//argc是命令行参数的数量,argv[]中每个字符指针指向一个命令行参数的字符串
{
int i;
for(i = 1; i < argc; i++){
write(1, argv[i], strlen(argv[i])); // 将参数内容写入标准输出
if(i + 1 < argc){//如果还有下一个参数
write(1, " ", 1);//输出空格
} else {//如果没有下一个参数
write(1, "\n", 1);//输出换行符
}
}
exit(0);
}结合实验给的提示信息,完成
user/sleep.c,主要的工作是进行参数验证,之后直接使用系统调用sleep即可1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
int
main(int argc, char *argv[]){
if(argc!=2){//如果参数数量不正确
//输出错误信息,给用户说明正确的用法
//输出错误信息的格式和源码下grep.c相同
fprintf(2, "usage: sleep [ticks num]\n");
exit(1);
}
else{//参数数量正确
int ticksNum = atoi(argv[1]);//获取参数
sleep(ticksNum);//系统调用sleep
}
exit(0);
}在Makefile的UPROGS中添加sleep,重新输入
make qemu编译即可![image1_3.png]()
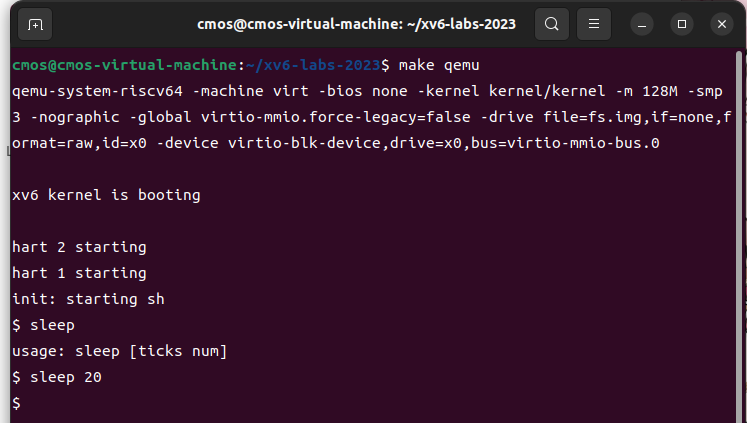
测试运行结果:
![image1_4.png]()
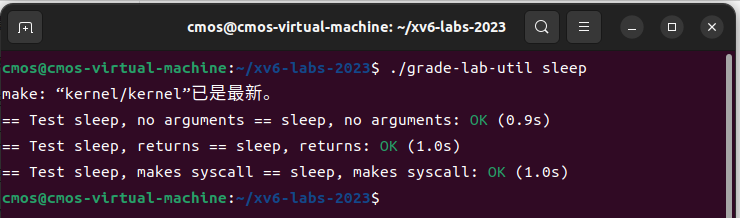
可以使用
./grade-lab-util sleep进行评分。![image1_5.png]()
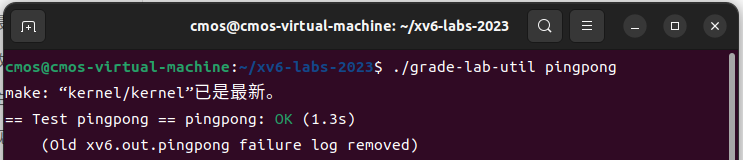
3. pingpong (easy)
Write a user-level program that uses xv6 system calls to ‘’ping-pong’’ a byte between two processes over a pair of pipes, one for each direction. The parent should send a byte to the child; the child should print “
: received ping”, where is its process ID, write the byte on the pipe to the parent, and exit; the parent should read the byte from the child, print “ : received pong”, and exit. Your solution should be in the file user/pingpong.c.
实现一个程序ping-pong,简而言之就是,父进程向子进程使用管道发送一个字节,这个过程叫“ping”,子进程向父进程发送一个字节,这个过程叫“pong”。
1 | |
测试截屏:
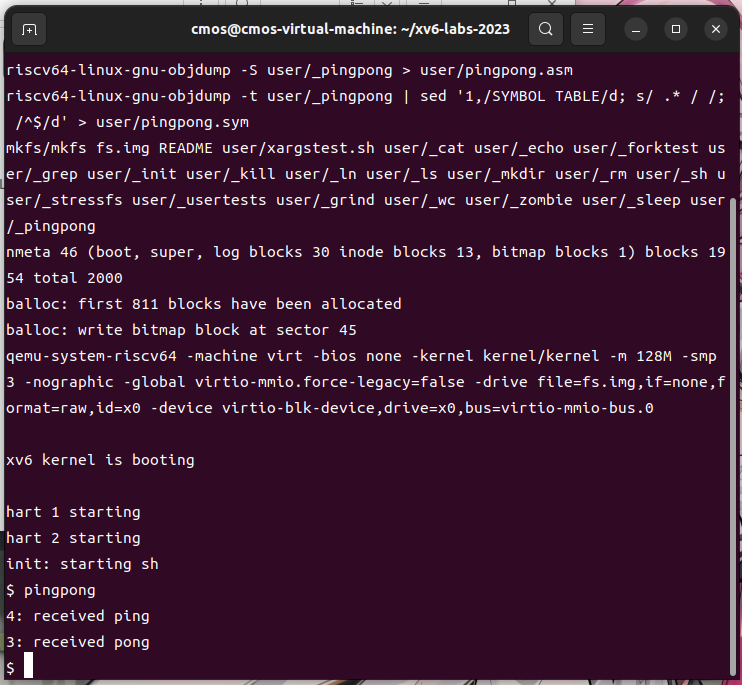
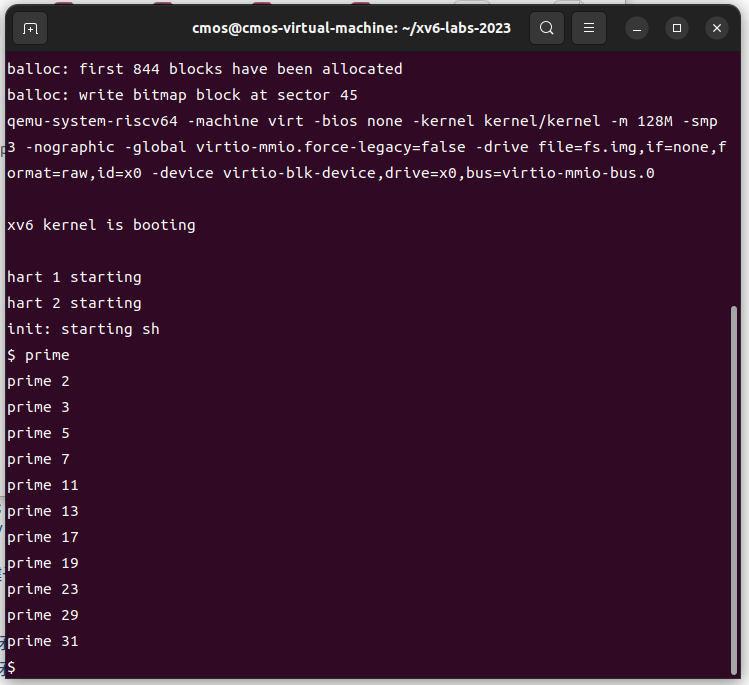
4.primes (moderate)/(hard)
Write a concurrent prime sieve program for xv6 using pipes and the design illustrated in the picture halfway down this page and the surrounding text. This idea is due to Doug McIlroy, inventor of Unix pipes. Your solution should be in the file
primes.c.
本实验较难,阅读了Bell Labs 和 CSP 线程 (swtch.com),大致了解原理,主进程把2到35输入管道的写入端,第一个子进程从读取端读取并判断其是否能被2整除,如果可以且不是2本身则不是质数,就停止;如果不能被2整除,由子进程的子进程去判断其能否被3整除;如此循环往复。具体实现时,使用递归来创建线程。
以下我初次完成时的错误代码,它计算到prime 13后,由于空间或系统的限制,无法输出后面的质数,最高只能输出至index为6。由于未认真审题,这段代码并不符合Prime sieve 素数筛算法,当然它的部分思路是对的。
1 | |
修改的后的代码:
1 | |
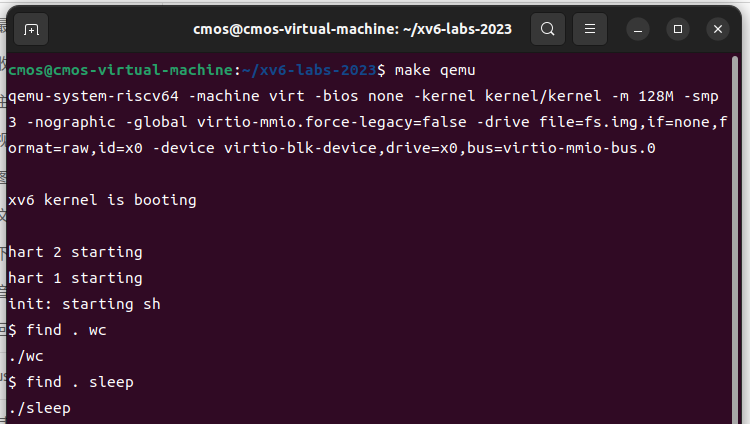
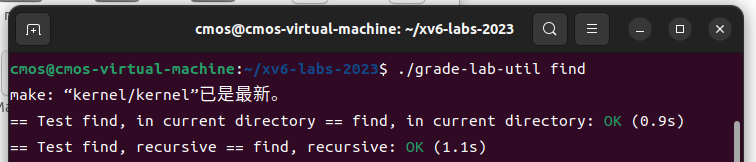
5.find (moderate)
Write a simple version of the UNIX find program for xv6: find all the files in a directory tree with a specific name. Your solution should be in the file
user/find.c.
Look at user/ls.c to see how to read directories,这部分内容见下方代码块注释
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67char* fmtname(char *path) { //返回文件路径中的文件名
static char buf[DIRSIZ+1];
char *p;
for(p=path+strlen(path); p >= path && *p!= '/'; p--) // 在路径字符串中找到最后一个斜杠字符
;
p++;
if(strlen(p)>= DIRSIZ) // 如果文件名长度大于缓冲区大小DIRSIZ,这个长度于kernel/fs.h中定义
return p; // 返回文件名指针 p
memmove(buf,p,strlen(p)); // 否则将文件名复制到buf 中
memset(buf+strlen(p),' ',DIRSIZ-strlen(p)); // 在文件名后面填充空格
return buf;
}
void ls(char *path) { //显示指定路径下的文件和目录信息
char buf[512],*p;
int fd;
struct dirent de;
struct stat st;
if((fd=open(path,O_RDONLY))<0) {//以只读模式打开指定路径,若无法打开则打印错误信息并返回
fprintf(2,"ls: cannot open %s\n",path);
return;
}
if(fstat(fd,&st)<0) { // 获取文件状态信息
fprintf(2,"ls: cannot stat %s\n",path); // 若失败则打印错误信息并关闭文件描述符
close(fd);
return;
}
switch(st.type) { // 选择文件类型
case T_DEVICE:
case T_FILE: // 文件及设备文件
printf("%s %d %d %l\n",fmtname(path),st.type,st.ino,st.size);
break;
case T_DIR: // 目录文件
if(strlen(path)+1+DIRSIZ+1>sizeof buf) {// 路径名过长
printf("ls: path too long\n");
break;
}
strcpy(buf,path); // 将路径复制到buf中
p=buf+strlen(buf);
*p++='/'; //加一个斜杠
while(read(fd,&de,sizeof(de))==sizeof(de)){ // 读取目录中的文件或子目录信息
if(de.inum==0)
continue;
memmove(p,de.name,DIRSIZ);// 将文件名复制到缓冲区p中
p[DIRSIZ]=0;
if(stat(buf,&st)<0) {// 获取文件名的状态信息
printf("ls: cannot stat %s\n",buf);
continue;
}
printf("%s %d %d %d\n",fmtname(buf),st.type,st.ino,st.size);// 打印文件或子目录的信息
}
break;
}
close(fd);
}
int main(int argc,char *argv[]){
int i;
if(argc<2) {
ls("."); // 如果没有额外参数,则打印当前目录的信息
exit(0);
}
for(i=1;i<argc;i++) {
ls(argv[i]); // 遍历每个参数
}
exit(0);
}参考上面user/ls.c中的部分文件,对其中的ls函数进行修改,完成user/find.c,要求输入文件名,返回该文件的路径(存在同名文件返回多个)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75#include "kernel/types.h"
#include "kernel/fcntl.h"
#include "kernel/stat.h"
#include "kernel/fs.h"
#include "user/user.h"
// 用于提取文件路径中的文件名部分
char* fmtname(char *path);
// 用于在文件系统中查找指定的文件或目录
void find(char *path,char *name);
int main(int argc,char *argv[]){
if(argc == 3 ) {
// 如果有三个命令行参数,调用 'find' 函数执行查找操作
find(argv[1],argv[2]);
exit(0);
}else {
printf("find: argv error!\n");
}
exit(0);
}
char* fmtname(char *path){
static char buf[DIRSIZ+1];
char *p;
for(p=path+strlen(path);p>=path&&*p!='/';p--);
p++;
memmove(buf,p,strlen(p)+1);
return buf;
}
// find 函数的定义
void find(char *path,char *name) {
char buf[512],*p;
int fd;
struct dirent de;
struct stat st;
if((fd = open(path,O_RDONLY))<0) {
fprintf(2,"ls: cannot open %s\n",path);
return;
}
if(fstat(fd,&st)<0) {
fprintf(2,"ls: cannot stat %s\n",path);
close(fd);
return;
}
switch(st.type) {
// 根据文件类型进行不同的处理
case T_DEVICE:
case T_FILE:
if(strcmp(fmtname(path),name)==0){
// 如果文件名与目标文件名匹配,打印文件路径
printf("%s\n",path);
}
break;
case T_DIR:
if(strlen(path)+1+DIRSIZ+1>sizeof buf) {
printf("ls: path too long\n");
break;
}
// 将路径复制到缓冲区(buf)中,并在末尾添加一个斜杠('/')
strcpy(buf,path);
p=buf+strlen(buf);
*p++='/';
// 读取文件或目录列表,并递归调用 'find' 函数进行查找
while(read(fd, &de, sizeof(de)) == sizeof(de)){
if(de.inum == 0 || de.inum == 1 || strcmp(de.name,".")==0 || strcmp(de.name,"..")==0)
continue;
memmove(p, de.name, strlen(de.name));
p[strlen(de.name)] = 0;
find(buf,name);
}
break;
}
close(fd);
}![image1_9.png]()
![image1_10.png]()
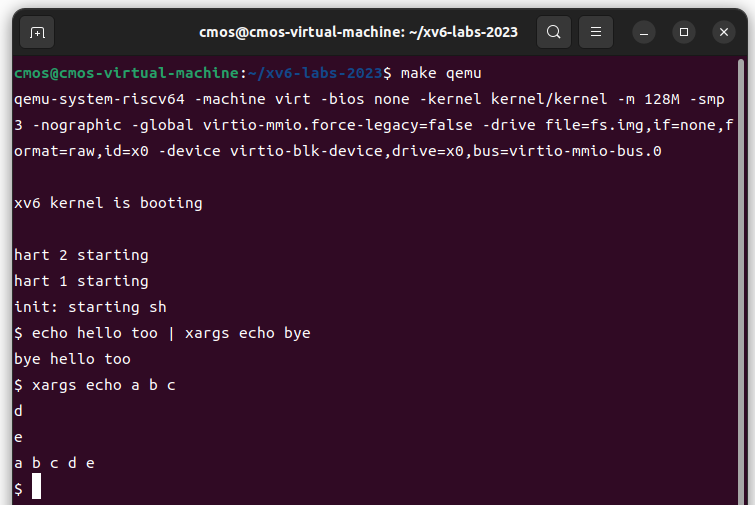
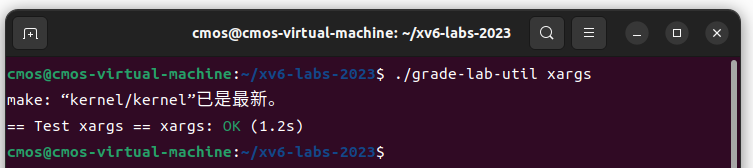
6.xargs (moderate)
Write a simple version of the UNIX xargs program for xv6: its arguments describe a command to run, it reads lines from the standard input, and it runs the command for each line, appending the line to the command’s arguments. Your solution should be in the file
user/xargs.c.
参考xargs 命令使用_xarg怎么使用-CSDN博客 理解了xargs命令的用法,当然这里只需实现简化的xargs
在
kernel/param.h声明过MAXARG,直接引用输入末尾存在换行符,要去掉
简而言之,就是使用
fork和exec,将参数保存后再一起执行,实现多参数1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62#include "kernel/types.h"
#include "kernel/stat.h"
#include "kernel/param.h"
#include "user/user.h"
#define MAXLENGTH 512
int main(int argc, char *argv[]) {
if (argc < 2) { // 如果命令行参数数量小于 2
fprintf(2, "usage: xargs [arguments]\n"); // 打印使用说明
exit(1); // 退出程序
}
char buf[1]; //单字节缓冲区,从输入中读取字节存放于此
char line_buf[MAXLENGTH]; //单行的缓冲区,每次读出来一个字节存到这里
int arg_num, byte_num; //前面是参数数量,后面是参数的字节数量
char *args[MAXARG]; //参数数组
int flag = 1;
for (int i = 1; i < argc; ++i) { // 将命令行参数添加到参数数组中(除了 xargs 本身)
args[i - 1] = argv[i]; //先把本身的参数存进去
}
arg_num = argc - 1;//本身的参数已经存入,计数
//第一个while循环,循环读取每一行
while (flag) {
byte_num = 0; //每次开始读行时,字节数归零
// 第二个while循环,循环读取一行中的每一个字节,直到遇到换行符
while ((flag = read(0, buf, 1)) && buf[0] != '\n') {
if (buf[0] != ' ') { //如果不是空格
line_buf[byte_num++] = buf[0];
} else { //如果是空格
if (byte_num > 0) { //如果缓冲区有内容
args[arg_num++] = (char *)malloc(byte_num + 1); //为参数分配内存
memmove(args[arg_num - 1], line_buf, byte_num); //复制缓冲区内容到参数
args[arg_num - 1][byte_num] = 0; //添加字符串结束符
byte_num = 0; //重置字节数
}
}
if (byte_num > MAXLENGTH) { //检查字节数是否超过限制
printf("xargs: input overflow!\n"); //打印错误消息
exit(1); //退出程序
}
}
if (byte_num > 0) { //如果缓冲区有内容(处理最后一个单词)
args[arg_num++] = (char *)malloc(byte_num + 1); //为参数分配内存
memmove(args[arg_num - 1], line_buf, byte_num); //复制缓冲区内容到参数
args[arg_num - 1][byte_num] = 0; //添加字符串结束符
}
if (arg_num > MAXARG) { //检查参数数量是否超过限制
printf("xargs:arguments overflow!\n"); //打印错误消息
exit(1); //退出程序
}
}
if (!fork()) { //创建子进程
exec(args[0], args); //执行命令
exit(1); //子进程退出
} else {
wait(0); //父进程等待子进程结束
}
exit(0);
}上述代码,第一个while循环负责控制每行的输入,第二个负责每个字节的输入,读取到换行符或者空格,就判定为一个参数存入参数数组,同时对单个参数和参数数量均进行判断,存在错误时结束程序。
![image1_11.png]()
![image1_12.png]()